| CPC G06F 16/2358 (2019.01) [G06F 16/2365 (2019.01); G06F 16/254 (2019.01)] | 18 Claims |
|
1. A system that processes optimal change data capture on a Hadoop cluster of data nodes, the system comprising:
an application component that receives change data;
a memory component that stores change data; and
a computer server coupled to the application component and the memory, the computer server comprising a programmed computer hardware processor configured to perform the steps of:
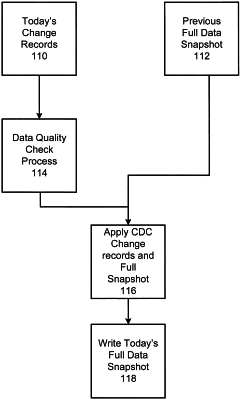
receiving a change data capture file containing specific records of changes for a current time period with respect to the application component;
receiving a previous full data snapshot file for a time period prior to the current time period;
execute a quality check process for each of a plurality of attributes on the change data capture file by forced parallelism that utilizes more Hadoop data nodes than a default number of Hadoop data nodes for the size of the change data capture file;
performing a join operation between the change data capture file and the previous full data snapshot to create a full data snapshot file for the current time period, wherein the join operation is performed under a large layout, which forces parallelism on an increased number of Hadoop data nodes greater than the default number of Hadoop data nodes for the size of the change data capture file; and
writing the full data snapshot for the current time period to the memory component.
|