| CPC G06F 16/1752 (2019.01) [G06F 16/152 (2019.01)] | 20 Claims |
|
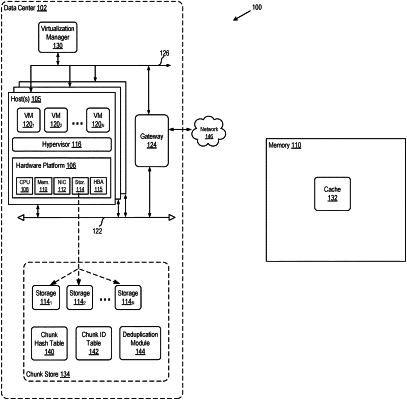
1. A method of deduplicating a first file, the method comprising:
separating the first file into a first plurality of chunks;
choosing a first chunk of the first file;
determining a hash of the first chunk is not in a chunk hash data structure stored in a chunk store;
determining, for a subset of the first plurality of chunks that is a percentage of the first plurality of chunks and that is less than all the first plurality of chunks, whether a hash of each of the chunks of the subset is in the chunk hash data structure, wherein each chunk of the subset of the first plurality of chunks is randomly selected from among all of the first plurality of chunks of the first file; and
based on the determining for the subset that none of the hashes of the chunks of the subset are in the chunk hash data structure, including at least one of the chunks of the subset in the chunk hash data structure without including all of the first plurality of chunks in the chunk hash data structure.
|