| CPC G06F 11/34 (2013.01) [G06F 17/18 (2013.01); G06N 20/00 (2019.01); H03M 7/3082 (2013.01); H03M 7/3084 (2013.01); H03M 7/6011 (2013.01)] | 20 Claims |
|
1. A method, comprising:
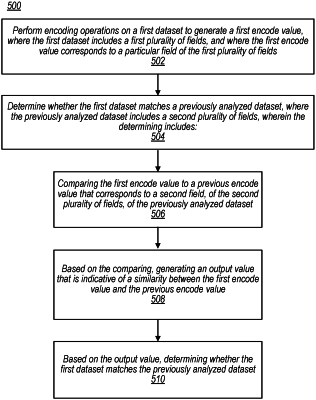
performing, by a data monitoring system, encoding operations on a first dataset to generate a set of encode values including first and second encode values generated using different types of encoding, wherein the first dataset includes first data organized into a first plurality of fields, the first data includes data records having data values for multiple fields within the first plurality of fields, and the first encode value corresponds to a particular field of the first plurality of fields;
determining, by the data monitoring system, whether the first dataset matches a previously analyzed dataset, wherein the previously analyzed dataset includes second data organized into a second plurality of fields, the second data includes data records having data values for multiple fields within the second plurality of fields, and the determining includes:
comparing the set of encode values to a previous set of encode values, wherein the previous set of encode values includes third and fourth encode values generated using different types of encoding and the third encode value corresponds to a second field, of the second plurality of fields, of the previously analyzed dataset;
based on the comparing, generating an output value that is indicative of a similarity between the set of encode values and the previous set of encode values; and
based on the output value, determining whether the first dataset matches the previously analyzed dataset.
|