| CPC G06F 11/1469 (2013.01) [G06F 9/45558 (2013.01); G06F 11/203 (2013.01); G06F 11/2023 (2013.01); G06F 2009/45575 (2013.01); G06F 2201/84 (2013.01)] | 18 Claims |
|
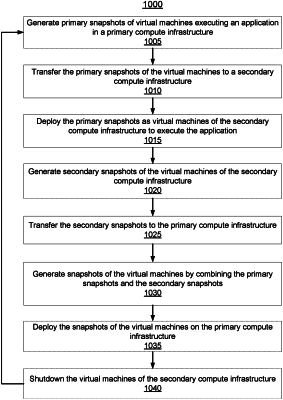
1. A method for failover and failback of an application between a primary compute infrastructure and a secondary compute infrastructure, the method comprising:
generating primary snapshots of virtual machines of the application in the primary compute infrastructure before the failover at a frequency defined by a service level agreement;
transferring the primary snapshots to the secondary compute infrastructure for deployment as virtual machines in the secondary compute infrastructure;
receiving secondary snapshots of the virtual machines of the application in the secondary compute infrastructure, the secondary snapshots being generated during the failover from the primary compute infrastructure to the secondary compute infrastructure at the frequency defined by the service level agreement, wherein a first data management and storage (DMS) cluster is coupled to the primary compute infrastructure to generate the primary snapshots and a second DMS cluster is coupled to the secondary compute infrastructure to generate the secondary snapshots, and wherein the frequency for generating the primary and secondary snapshots is shared by the first DMS cluster and the second DMS cluster;
initiating the failback from the secondary compute infrastructure to the primary compute infrastructure;
constructing a current state of the application by combining the primary snapshots generated before the failover and the secondary snapshots generated during the failover; and
deploying the application in the current state by deploying virtual machines on the primary compute infrastructure.
|