| CPC G06F 9/3802 (2013.01) [G06F 9/3001 (2013.01); G06F 9/30018 (2013.01); G06F 9/30145 (2013.01)] | 20 Claims |
|
1. A graphics processor comprising:
an instruction cache to store a set of instructions for execution;
a plurality of processing resources configured to execute instructions; and
circuitry configured to:
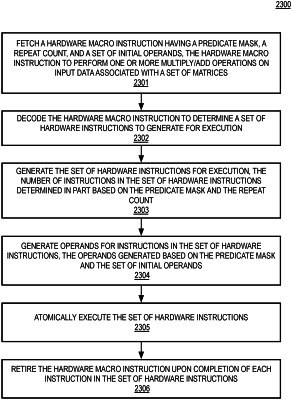
fetch a hardware macro instruction having a predicate mask, a repeat count, and a set of initial operands, wherein the hardware macro instruction is to cause the plurality of processing resources to perform a set of multiply and add operations on input associated with a set of matrices;
atomically execute the set of multiply and add operations via the plurality of processing resources in response to the hardware macro instruction, the set of multiply and add operations executed based on the predicate mask and the repeat count, wherein to atomically execute the set of multiply and add operations includes to execute a first multiply and add operation associated a first active bit within the predicate mask, bypass execution of a second multiply and add operation for a first inactive bit within the predicate mask, and execute a third multiply and add operation for a second active bit within the predicate mask; and
retire the hardware macro instruction upon completion of the set of multiple multiply and add operations.
|