| CPC G06F 9/30014 (2013.01) [G06F 9/30109 (2013.01); G06F 9/30145 (2013.01); G06F 17/16 (2013.01)] | 21 Claims |
|
1. An apparatus comprising:
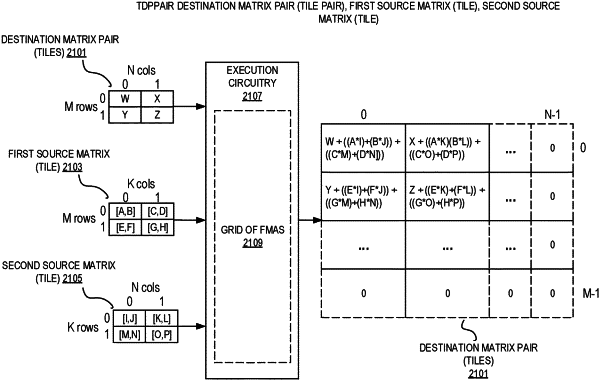
decode circuitry configured to decode at least an instance of a single instruction having fields to identify a first source matrix operand, a second source matrix operand, a destination matrix pair operand, and indicate an opcode, the opcode to indicate execution circuitry, in response to the decoded instance of the single instruction, is to compute a result by performing dot product operations on data elements from the identified first source matrix operand and the identified second source matrix operand, and accumulate the result into data element positions of the destination matrix pair operand, wherein a size of data element positions of the destination matrix pair operand is larger than a size of the data elements of the identified first source matrix operand and the identified second source matrix operand, wherein the execution circuitry comprises a plurality of fused-multiply adders and wherein the identified destination matrix pair operand comprises two matrix operands, each of the matrix operands comprising a group of packed data registers to logically represent a matrix operand; and
the execution circuitry configured to execute the decoded instance of the single instruction according to the opcode, wherein the execution circuitry comprises a plurality of fused-multiply adders configured to perform dot product operations on data elements from the identified first source matrix operand and the identified second source matrix operand and accumulate the result into data element positions of the destination matrix pair operand by at least using a first row of the first source matrix operand and the second column of the second source matrix operand and accumulating a result in a [0,1] data element position of the destination matrix pair operand, wherein the size of data elements of the destination matrix pair operand is larger than a size of data elements of the identified first source matrix operand and the identified second source matrix operand.
|