| CPC G06N 20/00 (2019.01) [G06F 9/5038 (2013.01); G06N 5/02 (2013.01); G06F 2209/5011 (2013.01)] | 14 Claims |
|
1. A computer-implemented method for determining whether a computer file comprises malicious code, the method comprising:
receiving a query at a query interface about whether a computer file comprises malicious code;
determining, using at least one machine learning sub model, whether the computer file comprises malicious code, the sub model corresponding to a type of the computer file; and
providing, to the query interface, data characterizing the determination,
wherein the sub model is generated using operations comprising:
receiving computer files at a collection interface;
generating multiple sub populations of the computer files based on respective types of the computer files;
generating a random training set and a random testing set from the computer files of each of the sub populations; and
generating at least one sub model for each random training set using steps comprising:
extracting sets of features from each of the computer files of that random training set, each set of features corresponding to the type of the computer files of that random training set, the set of features including at least one feature selected from the group consisting of file size, information density, structured layout, program section name, and author detail; and
training the at least one sub model using the corresponding random training set; and
validating the trained at least one sub model using the random testing set for that sub population;
wherein the determining comprises:
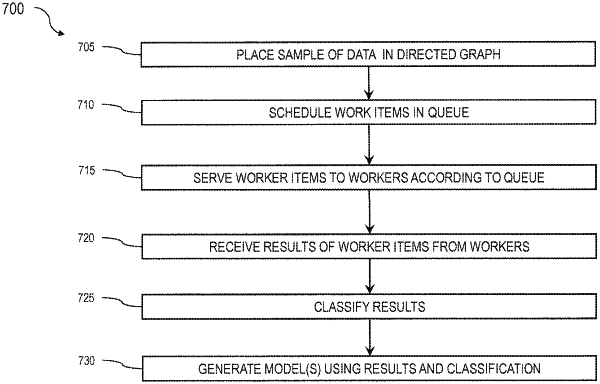
scheduling work items according to at least a sample prioritization or a worker rate;
placing the computer file within a directed acyclic graph represented as a queue of work items for a particular worker class, wherein the directed acyclic graph comprises a plurality of hierarchical nodes in which nodes are based on the scheduling and are represented as individual worker items that are used to process the computer file;
serving the work items to the workers according to the queue;
receiving results from the workers for the work items; and
classifying the computer file based on the received results to indicate whether or not the computer file likely comprises malicious code;
wherein:
the nodes of the directed graph are traversed based on the received results;
each work item comprises one or more tasks to effect extraction from the computer file;
each worker class represents a set of extracted features and is associated with a specific sample type; and
the sample of data comprises files for access or execution by a computing system.
|