| CPC G10L 25/78 (2013.01) [G10L 21/0272 (2013.01); G10L 25/18 (2013.01); G10L 25/30 (2013.01)] | 10 Claims |
|
1. A method for detecting a voice from audio data, performed by a computing device including at least one processor, the method comprising:
obtaining audio data;
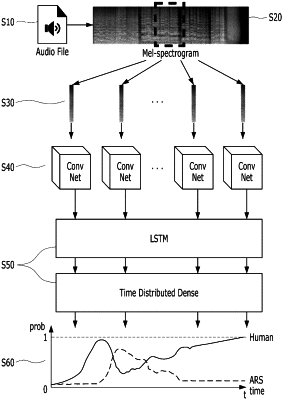
generating image data based on a spectrum of the obtained audio data;
extracting a feature on the image data by utilizing a first neural network model; and
extracting a time-series feature of the image data by utilizing a second neural network model sequentially connected with the first neural network model;
determining whether an automated response system (ARS) voice is included in each of a plurality of sections of the audio data, based on the feature on the image data and the time-series feature of the image data;
eliminating a section including the ARS voice, among the plurality of sections of the audio data; and
generating input data or training data for analysis of spoken voice based on remaining sections excluding the eliminated section, among the plurality of sections of the audio data.
|