| CPC G10L 15/16 (2013.01) [G10L 15/063 (2013.01); G10L 15/18 (2013.01)] | 20 Claims |
|
1. An electronic device comprising:
at least one processor; and
a memory operatively connected to the at least one processor and configured to store at least one language model,
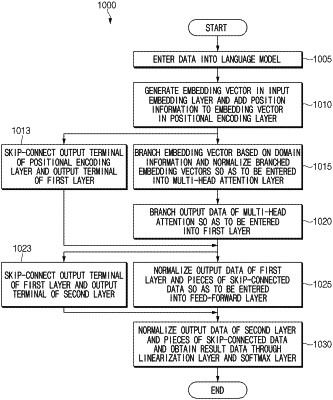
wherein the language model includes an input embedding layer, a positional encoding layer, at least one sub-network layer, a linearization layer, and a softmax layer,
wherein the at least one sub-network layer includes a linear normalization layer, a multi-head attention layer, a first layer including a plurality of first adapter modules respectively corresponding to different domains included in the at least one language model, a feed-forward layer, and a second layer including a plurality of second adapter modules respectively corresponding to the different domains in the at least one language model, wherein the different domains correspond to different contacts on a contact list or correspond to different applications,
wherein the at least one processor is configured to:
enter data into the language model, generate an embedding vector based on the data in the input embedding layer, and add position information to the embedding vector in the positional encoding layer;
branch the embedding vector based on domain information included in the embedding vector, normalize the branched embedding vectors using the linear normalization layer, and enter the normalized embedding vectors into the multi-head attention layer;
branch output data of the multi-head attention layer into one or more of the plurality of first adapter modules of the first layer corresponding to the domain information included is the embedding vector, normalize pieces of output data of the first layer, and enter the normalized pieces of output data of the first layer into the feed-forward layer;
branch output data of the feed-forward layer into one or more of the plurality of second adapter modules of the second layer corresponding to the domain information included in the embedding vector and normalize pieces of output data of the second layer; and
enter the normalized pieces of output data of the second layer into the linearization layer and the softmax layer to obtain result data.
|