| CPC G06V 40/176 (2022.01) [G06T 5/20 (2013.01); G06V 10/44 (2022.01); G06V 10/764 (2022.01); G06V 10/814 (2022.01); G06V 40/161 (2022.01)] | 8 Claims |
|
1. A dynamic facial expression recognition (FER) method based on a Dempster-Shafer (DS) theory, comprising the following steps:
a) preprocessing video data V in a dataset, extracting last N frames of the video data V to obtain consecutive video frames, and performing face detection, alignment, and clipping operations on the video frames to obtain a facial expression image P;
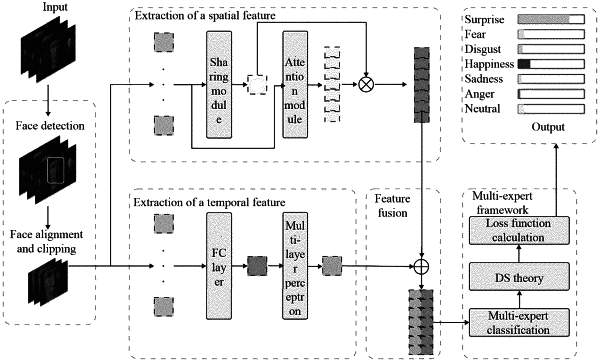
b) constructing a Dempster-Shafer theory Expression Recognition (DSER) network model, wherein the DSER network model comprises a same-identity inter-frame sharing module Ms a space-domain attention module M att a time-domain fully connected (FC) unit VFC, a time-domain multi-layer perceptron unit VMLP, a spatio-temporal feature fusion module Mst, and a discriminator Dds guided by a DS theory;
c) separately inputting the facial expression image P into the same-identity inter-frame sharing module Ms and the space-domain attention module Matt in the DSER network model, to obtain a same-identity inter-frame shared feature FsP and a space-domain attention feature FattP, and multiplying the same-identity inter-frame shared feature FsP by the space-domain attention feature FattP to obtain a space-domain feature FsattPS;
d) sequentially inputting the facial expression image P into the time-domain FC unit VFC and the time-domain multi-layer perceptron unit VMLP in the DSER network model to obtain a time-domain vector VFCMLPPT;
e) inputting the space-domain feature FsattPS and the time-domain vector VFCMLPPT into the spatio-temporal feature fusion module Mst in the DSER network model to obtain a spatio-temporal feature FstP;
f) inputting the spatio-temporal feature FstP into the discriminator Dds guided by the DS theory in the DSER network model, to obtain a classification result R, and completing the construction of the DSER network model;
g) calculating a loss function l;
h) iterating the DSER network model by using the loss function l and an Adam optimizer, to obtain a trained DSER network model; and
i) processing to-be-detected video data by using the step a), to obtain a facial expression image, and inputting the facial expression image into the trained DSER network model to obtain the classification result R.
|