| CPC G06V 40/165 (2022.01) [G06V 10/247 (2022.01); G06V 10/62 (2022.01); G06V 10/7715 (2022.01); G06V 10/806 (2022.01); G06V 10/82 (2022.01); G06V 20/41 (2022.01); G06V 40/171 (2022.01); G06V 40/174 (2022.01); G06V 10/774 (2022.01)] | 6 Claims |
|
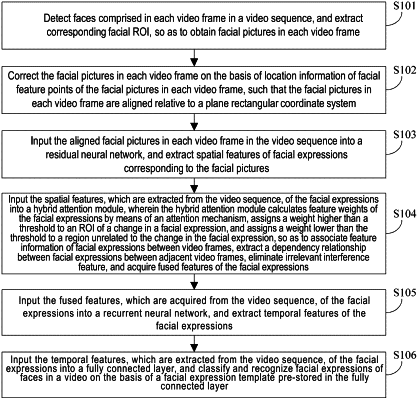
1. A facial expression recognition method combined with an attention mechanism, comprising following steps:
detecting a face comprised in each of video frames in a video sequence, and extracting a corresponding facial region of interest (ROI), so as to obtain a facial picture in each of the video frames;
correcting the facial picture in each of the video frames on the basis of location information of a facial feature point of the facial picture in each of the video frames, so that the facial picture in each of the video frames is aligned relative to a plane rectangular coordinate system;
inputting the aligned facial picture in each of the video frames of the video sequence into a residual neural network, and extracting a spatial feature of a facial expression corresponding to the facial picture;
calculating a feature weight of the facial expression through an attention mechanism using the spatial feature of the facial expression extracted from the video sequence, a weight higher than a threshold is assigned to an ROI of a facial expression change and a weight lower than the threshold is assigned to a region irrelevant to the facial expression change to correlate feature information of the facial expression between the video frames, a dependency relationship of the facial expression between the adjacent video frames is extracted, and irrelevant interference features are eliminated to acquire a fused feature of the facial expression;
inputting the fused feature of the facial expression acquired from the video sequence into a recurrent neural network, and extracting a temporal feature of the facial expression;
inputting the temporal feature of the facial expression extracted from the video sequence into a fully connected layer, and classifying and recognizing the facial expression in a video based on a facial expression template pre-stored in the fully connected layer.
|