| CPC G06N 3/08 (2013.01) [G06N 3/04 (2013.01)] | 20 Claims |
|
1. A deep learning network accelerator comprising:
an encoder to compress an input activation vector and a weight vector to reduce sparsity therein, thereby generating a compressed input activation vector and a compressed weight vector;
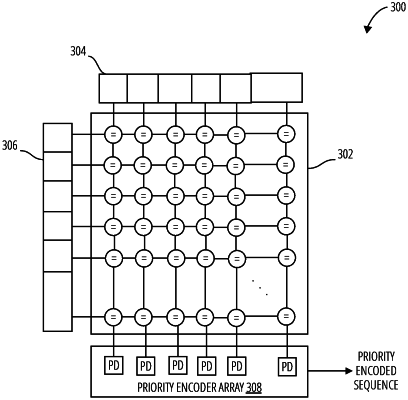
a parallelism discovery unit to compare coordinate indexes for the compressed weight vector and for the compressed input activation vector to generate matching pairs of coordinate indexes;
a decoder to generate column selects and row selects from the matching pairs, the column selects and row selects comprising validity markers and addresses for the matching coordinate indexes; and
an array of computing elements to receive the column selects and the row selects from the decoder and to transform the column selects, the row selects, the compressed input activation vector, and the compressed weight vector into output activations of a deep learning network.
|