| CPC G06F 18/21 (2023.01) [G06N 3/04 (2013.01); G06T 1/60 (2013.01); G06V 10/95 (2022.01)] | 9 Claims |
|
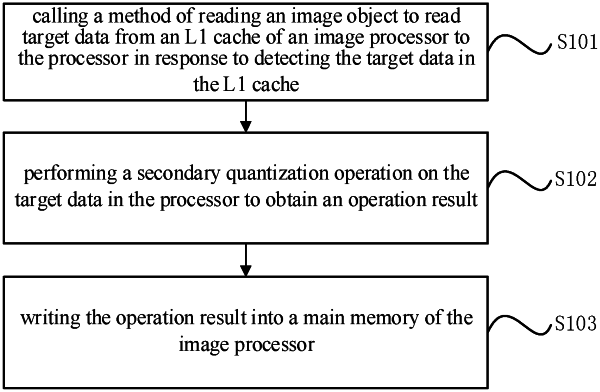
1. A method for optimizing a deep learning operator, applicable in a processor, comprising:
calling a method of reading an image object to read target data from an L1 cache of an image processor to the processor in response to detecting the target data in the L1 cache, wherein the target data comprises data to be inputted into a current network layer of a neural network model and the target data is fixed-point data obtained after performing a quantization operation on data to be quantized in advance, and the data to be quantized is one of: float-point data of an initial network layer of the neural network model and fixed-point data outputted from a network layer previous to the current network layer;
performing a secondary quantization operation on the target data in the processor to obtain an operation result; and
writing the operation result into a main memory of the image processor;
wherein, a number of digits in the fixed-point data is a first preset number, wherein the first preset number is 8 or 16; the target data comprises a weight and an offset value of the current network layer, and output data outputted from the network layer previous to the current network layer;
wherein performing the secondary quantization operation on the target data in the processor to obtain the operation result comprises:
performing an operation on the output data based on the weight to obtain a first operation value and obtaining a cumulative result of the first operation value and the offset value, wherein a number of digits in the cumulative result is a second preset number, and the second preset number is 32; and
performing the secondary quantization operation on the cumulative result to obtain the operation result, wherein a number of digits in the operation result is the first preset number.
|