| CPC G06F 12/0802 (2013.01) [G06F 13/1668 (2013.01); G06F 13/4027 (2013.01); G06F 2213/16 (2013.01); G06F 2213/40 (2013.01)] | 18 Claims |
|
1. A method comprising:
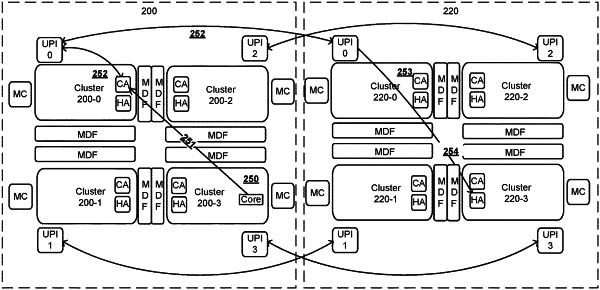
a processor, in a source cluster, selecting a target cluster from among two or more target clusters and issuing a cache coherence request to the selected target cluster via a first path, wherein
the selecting the target cluster is based on a memory map data that specifies which target cluster is physically closest to a die-to-die interconnect interface that is physically closest to the source cluster,
the selecting the target cluster from among the two or more target clusters minimizes a number of die boundary traversals and
the first path includes a first die-to-die interconnect interface for the source cluster and a second die-to-die interconnect interface to the selected target cluster and
the processor receiving a response to the cache coherence request and accessing a cache based on response, wherein the response comprises one or more of: no match, match with data, data shared, data exclusive owned and wherein the response traverses the first path but in an opposite direction to the source cluster from the selected target cluster.
|