| CPC B60W 30/0956 (2013.01) [G06N 3/045 (2023.01); G06N 3/0464 (2023.01); B60W 2300/125 (2013.01); B60W 2420/408 (2024.01); B60W 2554/4041 (2020.02); B60W 2554/80 (2020.02)] | 1 Claim |
|
1. A backward anti-collision driving decision-making method for a heavy commercial vehicle, wherein the method comprises the following steps:
step I: establishing a virtual traffic environment model: for high-class highways, establishing a virtual traffic environment model, that is, a three-lane virtual environment model comprising straight lanes and curved lanes, wherein the heavy commercial vehicle moves in the traffic environment model, a target vehicle follows the heavy commercial vehicle, and in the process there are 4 different running conditions, comprising acceleration, deceleration, uniform velocity and lane change;
in a process of establishing the virtual traffic environment model, vehicle movement state information is obtained in real time through a centimeter-level high-precision differential GPS, an inertia measurement unit and a millimeter wave radar mounted on each vehicle, comprising positions, velocity, acceleration, relative distance and relative velocity of the two vehicles; a type of the target vehicle is obtained in real time through a visual sensor mounted at a rear part of the vehicle; and drivers control information is read through a CAN bus, comprising a throttle opening and a steering wheel angle of the vehicle;
the target vehicle refers to a vehicle located behind the heavy commercial vehicle on a running road, located within the same lane line, running in the same direction and closest to the heavy commercial vehicle, including 3 types: small, medium and large vehicles;
step II: establishing a backward collision risk assessment model, specifically comprising:
firstly, calculating time required for collision between the heavy commercial vehicle and the target vehicle:
 in formula (1), RTTC(t) represents backward distance collision time at time tin unit of second, xc(t) represents vehicle distance in unit of meter, vF(t) and vR(t) respectively represent the velocity of the heavy commercial vehicle and the target vehicle, vr(t) represents the relative velocity of the two vehicles in unit of meter per second, and vr(t)=vF(t)−vR(t);
secondly, calculating a backward collision risk level; when the backward distance collision time is not less than 2.1 seconds and not more than 4.4 seconds, giving a backward collision alarm, indicating that a backward collision early warning system has passed a test; and based on this, quantifying the backward collision risk level:
 in formula (2), δw represents a quantified value of a backward collision risk; when δw≥1, it indicates that there is no backward collision risk; when 0.5≤δw≤1, it indicates that there is a backward collision risk; and when 0≤δw≤0.5, it indicates that the backward collision risk level is very high;
step III: establishing a backward anti-collision driving decision-making model of the heavy commercial vehicle: comprehensively considering the influence of traffic environment, vehicle operation state, rear vehicle type and backward collision risk level on backward collision, establishing a backward anti-collision driving decision-making model of the heavy commercial vehicle by adopting a PPO algorithm, and performing interactive iterative learning with a target vehicle movement random process model to obtain an optimal backward anti-collision decision, specifically comprising the following 4 sub-steps:
sub-step 1: defining basic parameters of the backward anti-collision driving decision-making model
firstly, describing a backward anti-collision driving decision-making problem as a Markov decision-making process (S,A,P,r) under a certain reward function, wherein S is a state space, A is a backward anti-collision action decision, P is a state transition probability caused by movement uncertainty of the target vehicle, and r is a reward function; and secondly, defining basic parameters of the Markov decision-making process, specifically comprising:
(1) defining a state space
establishing a state space expression by using the vehicle movement state information output in step I and the backward collision risk level output in step II:
St=(vF_lon,aF_lon,vr_lon,ar_lon,θstr,pthr,Lr,δw,Tm) (3)
In formula (3), St represents a state space at time t, vF_lon and vr_lon respectively represent the longitudinal velocity of the heavy commercial vehicle and the relative longitudinal velocity of the two vehicles in unit of meter per second, aF_lon and ar_lon respectively represent the longitudinal acceleration of the heavy commercial vehicle and the relative longitudinal acceleration of the two vehicles in unit of meter per square second, θstr represents a steering wheel angle of the vehicle in unit of degree, pthr represents a throttle opening in unit of percentage, Lr represents a relative vehicle distance in unit of meter, δw and Tm respectively represent the backward collision risk level and the type of the target vehicle, m=1, 2, 3 respectively represent that the target vehicle is a large vehicle, a medium vehicle and a small vehicle, and Tm=m in the present invention;
(2) defining an action decision
in order to comprehensively consider the influence of transverse movement and longitudinal movement on backward collision, defining a driving policy, that is, an action decision output by the decision-making model, by using the steering wheel angle and the throttle opening as control quantities in the present invention:
At=[θstr_out,pthr_out] (4)
in formula (4), At represents an action decision at time t, θstr_out represents a normalized steering wheel angle control quantity in a range of [−1, 1], and pthr_out represents a normalized throttle opening control quantity in a range of [0, 1]; and when pthr_out=0, it indicates that the vehicle does not accelerate, and when δbrake=1, it indicates that the vehicle accelerates at a maximum acceleration;
(3) establishing a reward function
in order to evaluate the advantages and disadvantages of the action decision, establishing a reward function to concretize and digitalize the evaluation; and considering that backward anti-collision driving decision-making is a multi-objective optimization problem involving safety, comfort and other objectives, designing the reward function as follows:
rt=r1+r2+r3 (5)
in formula (5), rt represents a reward function at time t, r1 represents a safety distance reward function, r2 represents a comfort reward function, and r3 represents a penalty function:
firstly, designing a safety distance reward function r1:
 in formula (6), Lr and Ls respectively represent relative vehicle distance and a safety distance threshold, ωd represents a safety distance weight coefficient, valued as ωd=0.85 in the present invention;
secondly, designing a comfort reward function r2:
r2=ωj|aF_lon(t+1)−aF_lon(t)| (7)
in formula (7), ωj is a comfort weight coefficient, valued as ωj=0.95 in the present invention;
finally, designing a penalty function r3:
 (4) designing an expected maximum policy
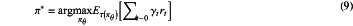 in formula (9), π* is an expected maximum policy, π is a backward anti-collision decision-making policy, γ is a discount factor, γϵ(0,1), and τ(π) represents trajectory distribution under policy π;
sub-step 2: designing a network architecture of the backward anti-collision driving decision-making model
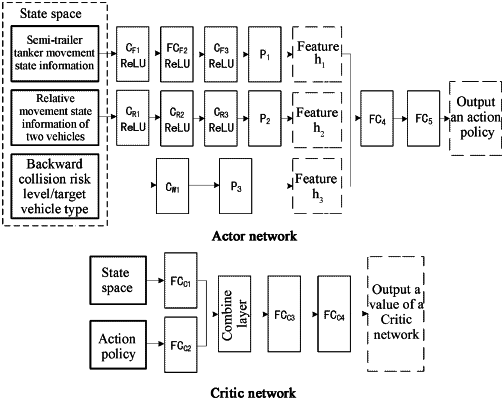
setting up a backward anti-collision driving decision-making network by using an “Actor-Critic” network framework, comprising an Actor network and a Critic network, wherein the Actor network uses state space information as an input and outputs an action decision, that is, the throttle opening and steering wheel angle control quantities of the heavy commercial vehicle; the Critic network uses the state space information and the action decision as an input, and outputs a value of current “state-action”, specifically comprising:
(1) designing an Actor network
establishing a hierarchical coder structure and respectively extracting features of various information in the state space; firstly, constructing 3 serially connected convolution layers (CF1, CF2, CF3) and 1 maximum pooling layer (P1), extracting features of the movement state information (longitudinal velocity, longitudinal acceleration, steering wheel angle, and throttle opening) of the vehicle, and coding them into an intermediate feature vector h1; extracting features of the relative movement state information (relative longitudinal velocity, relative longitudinal acceleration, and relative vehicle distance) of the two vehicles by using the same structure, that is, 3 serially connected convolution layers (CR1, CR2, CR3) and 1 maximum pooling layer (P2), and coding them into an intermediate feature vector h2; extracting features of the collision risk level and the type of the target vehicle by using a convolution layer CW1 and a maximum pooling layer P3, and coding them into an intermediate feature vector h3; and secondly, combining the features h1, h2 and h3 and connecting full connection layers FC4 and FC5 to output the action decision,
wherein the number of neurons of the convolution layers CF1, CF2, CF3, CR1, CR2, CR3 and CW1 is set to be 20, 20, 10, 20, 20, 10 and 20 respectively; the number of neurons of the full connection layers FC4 and FC5 is set to be 200; the activation function of each convolution layer and full connection layer is a Rectified Linear Unit (ReLU), and an expression thereof is f(x)=max (0, x);
(2) designing a Critic network
establishing a Critic network by using a neural network with a multiple hidden layer structure; firstly, inputting a state space St into a hidden layer FCC1; at the same time, inputting an action decision At into a hidden layer FCC2; secondly, combining the hidden layers FCC1 and FCC2 by tensor addition; and finally, after passing through the full connection layers FCC3 and FCC4 sequentially, outputting a value of the Critic network,
wherein the number of neurons of the layers FCC1 and FCC2 is set to be 400, the number of neurons of other hidden layers is set to be 200, and the activation function of each layer is an ReLU;
sub-step 3: training the backward anti-collision driving decision-making model performing gradient updating to the network parameters by using loss functions Jactor and Jcritic wherein a specific training process is as follows:
sub-step 3.1: initializing the Actor network and the Critic network;
sub-step 3.2: performing iterative solution, wherein each iteration comprises sub-step 3.21 to sub-step 3.4 specifically as follows:
sub-step 3.21: performing iterative solution, wherein each iteration comprises sub-step 3.211 to sub-step 3.213 as follows:
sub-step 3.211: obtaining a movement control operation of the vehicle by using the virtual traffic environment model in step I;
sub-step 3.212: obtaining sample data (St,At,ft) by using the Actor network;
sub-step 3.213: ending a cycle to obtain a sample point set [(S1,A1,r1), (S2,A2,r2), . . . , (St,At,rt)];
sub-step 3.22: calculating an advantage function:
 in formula (10), Ft represents an advantage function, V(St) represents a value function of state St, Ft>0 represents that the possibility of taking a current action should be increased, and Ft<0 represents that the possibility of taking the action should be decreased;
sub-step 3.23: performing iterative solution, wherein each iteration comprises sub-step 3.231 to sub-step 3.233 specifically as follows:
sub-step 3.231: calculating an objective function of the Actor network;
sub-step 3.232: updating the parameter Jactor of the Actor network:
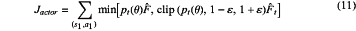 in formula (11), pt(θ) represents a ratio of a new policy πθ to an old policy πθ_old on action decision distribution in a policy updating process,
 clip(⋅) represents a clipping function, and ε is a constant valued as ε=0.25;
sub-step 3.233: updating the parameter Jcritic of the Critic network:
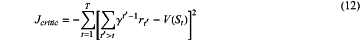 sub-step 3.234: ending a cycle;
sub-step 3.3: performing iterative updating according to the method provided in sub-step 3.2 to make the Actor network and the Critic network converge gradually, wherein in a training process, if the vehicle has a backward collision or rollover, a current round is terminated and a new round for training is started; and when the iteration reaches the maximum number of steps or the model is capable of making a backward anti-collision driving decision stably and accurately, the training ends;
sub-step 4: outputting the decision-making policy by using the backward anti-collision decision-making model
inputting the information obtained by the centimeter-level high-precision differential GPS, the inertia measurement unit, the millimeter wave radar and the CAN bus into the trained backward anti-collision driving decision-making model, such that proper steering wheel angle and throttle opening control quantities are capable of being quantitatively output to provide an effective and reliable backward anti-collision driving suggestion for a driver, so as to realize effective, reliable and adaptive backward anti-collision driving decision-making of the heavy commercial vehicle.
|