| CPC A61B 5/165 (2013.01) [A61B 5/4803 (2013.01); A61B 5/7275 (2013.01); G06F 18/253 (2023.01); G06N 3/08 (2013.01); G06T 7/0012 (2013.01); G06V 20/46 (2022.01); G06V 20/49 (2022.01); G10L 25/30 (2013.01); G10L 25/57 (2013.01); G10L 25/63 (2013.01); G10L 25/66 (2013.01); G06T 2207/10016 (2013.01)] | 10 Claims |
|
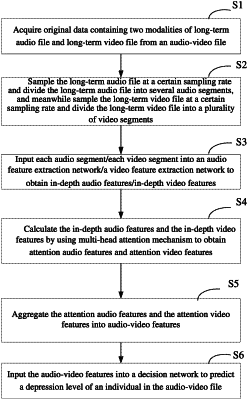
1. An automatic depression detection method using audio-video, characterized in that, the method comprises steps of:
S1, acquiring original data containing two modalities of long-term audio file and long-term video file from an audio-video file;
S2, sampling the long-term audio file at a certain sampling rate and dividing the long-term audio file into several audio segments, and meanwhile sampling the long-term video file at a certain sampling rate and dividing the long-term video file into a plurality of video segments;
S3, inputting each audio segment into an audio feature extraction network to obtain in-depth audio features, the audio feature extraction network comprising an expanded convolution layer and a time sequence pooling layer;
wherein inputting each audio segment into an audio feature extraction network to obtain in-depth audio features comprises: performing, firstly, convolution expanding on an input audio by three times, wherein a quantity of convolution kernels is set to 256, a size of convolution kernel is set to 2, an expansion rate is set to 2, a quantity of convolution layers is set to 4, a quantity of input channels is 1, a quantity of output channels is 256, and a data length is of 256; then, performing down-sampling through the time sequence pooling layer, wherein a quantity of channels and a data length are set to 128, respectively, so that the in-deep audio features contain time sequence dynamic information; and
inputting each video segment into a video feature extraction network to obtain in-depth video features, the video feature extraction network comprising a 3D convolution layer and a bidirectional long short-term memory network module;
wherein inputting each video segment into a video feature extraction network to obtain in-depth video features comprises: performing, firstly, 3D convolution on an input video frame, wherein a quantity of convolution kernels is set to 8, a size of convolution kernel is set to 3×3×3, and a step length is set to (2, 2, 2); then, inputting an output of the 3D convolution layer to the bidirectional long short-term memory network having a quantity of 64 output nodes to capture a time sequence representation of the video;
S4, calculating the in-depth audio features and the in-depth video features by using multi-head attention mechanism so as to obtain attention audio features and attention video features;
S5, aggregating the attention audio features and the attention video features into audio-video features through a feature aggregation model; and
S6, inputting the audio-video features into a decision network to predict a depression level of an individual in the audio-video file.
|