| CPC G06N 3/08 (2013.01) [G06N 3/045 (2023.01)] | 20 Claims |
|
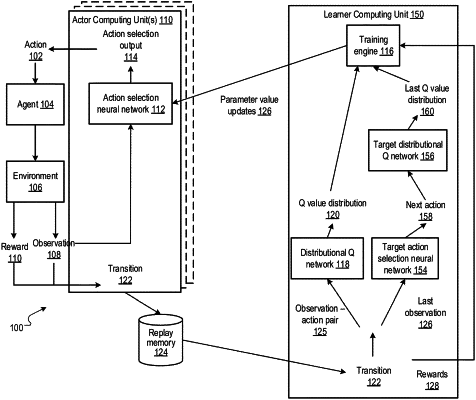
1. A computer-implemented method for training an action selection neural network having a plurality of action selection parameters and used to select actions to be performed by an agent interacting with an environment, wherein the action selection neural network is configured to receive an input observation characterizing a state of the environment and to map the input observation to an action, the method comprising:
maintaining a respective replica of the action selection neural network;
receiving an observation characterizing a current state of an instance of the environment;
generating a respective transition starting from the received observation by selecting actions to be performed by the agent using the action selection neural network replica and in accordance with current values of the action selection parameters;
storing respective data for the respective transition in a memory; and
using a transition sampled from the memory to train the action selection neural network, the sampled transition comprising at least an observation-action-reward triple, and the training comprising:
processing an observation-action pair in the observation-action-reward triple of the sampled transition to generate, for the triple, a distribution over possible returns that could result if the action is performed in response to the observation; and
determining an update to the action selection parameters using the distribution over the possible returns.
|