| CPC G06N 3/047 (2023.01) [G06F 40/279 (2020.01); G06F 40/44 (2020.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/084 (2013.01); G10L 13/04 (2013.01); G10L 13/086 (2013.01); G10L 15/16 (2013.01); G10L 25/30 (2013.01); G06F 17/18 (2013.01); G10H 2250/311 (2013.01)] | 20 Claims |
|
1. A neural network system implemented by one or more computers,
wherein the neural network system is configured to perform a sequence processing task by processing an input sequence of data elements comprising a plurality of data elements to generate a neural network output which characterizes the input sequence, and
wherein the neural network system comprises:
a convolutional subnetwork comprising a plurality of convolutional neural network layers, wherein the convolutional subnetwork is configured to, for each of the plurality of data elements:
receive a current input sequence comprising the data element and the data elements that precede the data element in the input sequence, and
process the current input sequence, in accordance with trained values of a set of neural network parameters of the convolutional subnetwork, to generate an alternative representation for the data element, wherein the trained values of the set of neural network parameters of the convolutional subnetwork have been determined by a machine learning training technique, wherein the convolutional neural network layers are causal convolutional neural network layers and the alternative representation for the data element does not depend on any data elements that follow the data element in the input sequence; and
an output subnetwork, wherein the output subnetwork is configured to receive the alternative representations of the data elements and to process the alternative representations to generate the neural network output characterizing the input sequence, wherein the neural network output comprises a plurality of sets of scores, wherein each set of scores includes a respective score for each of a plurality of possible outputs; and
a subsystem configured to select outputs in accordance with the sets of scores to generate an output sequence comprising a plurality of outputs;
wherein:
the neural network system is configured to perform speech recognition, the input sequence is an audio data input sequence of audio data elements, and the output sequence is a sequence of graphemes that is a grapheme representation of words spoken in the audio data input sequence; or
the neural network system is configured to perform speech recognition, the input sequence is an audio data input sequence of audio data elements, and the output sequence is a sequence of phonemes that is a phoneme representation of words spoken in the audio data input sequence; or
the neural network system is configured to perform speech recognition, the input sequence is an audio data input sequence of audio data elements, and the output sequence is a sequence of words in a first natural language that represents worked spoken in the audio data input sequence; or
the neural network system is configured to perform a language modeling task, the input sequence is a sequence of phonemes, and the output sequence is a sequence of words in a natural language that represents the input sequence; or
the neural network system is configured to perform a language modeling task, the input sequence is a sequence of graphemes, and the output sequence is a sequence of words in a natural language that represents the input sequence; or
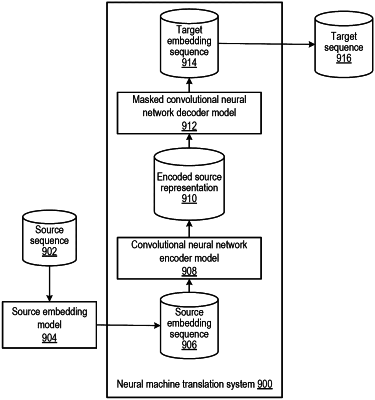
the neural network system is configured to perform machine translation, the input sequence is a sequence of words in a first natural language, and the output sequence is a sequence of words in a second natural language that is a translation of the input sequence into the second natural language; or
the neural network system is configured to perform a natural language processing task, the input sequence is a sequence of words in a natural language, and the output sequence is a sequence that classifies the words in in the input sequence according to a kind of output required by the natural language processing task; or
the neural network system is configured to perform a compression task, the input sequence is a sequence of data elements drawn from an input sample, and the output sequence is a compressed or encoded sample; or
the neural network system is configured to perform a medical analysis task, the input sequence is a sequence of health data elements for a particular patient, and the output sequence includes data that characterizes health of the patient or predicts future health of the patient.
|