| CPC G06F 40/295 (2020.01) | 21 Claims |
|
1. A method comprising:
receiving, by a natural language processing system, first natural language data representing an utterance;
generating, by an automatic speech recognition component, first text data representing the first natural language data;
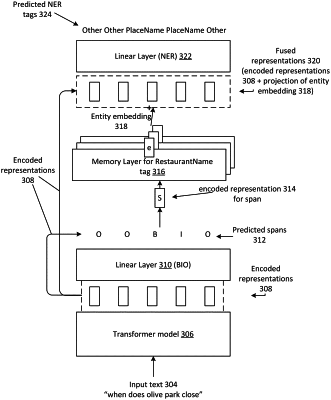
generating, by a transformer model, first embedding data comprising a first vector representation of the first text data in an embedding space, wherein the first embedding data encodes the first text data as a plurality of tokens;
determining first span data for the first embedding data, the first span data defining a grouping of one or more tokens of the plurality of tokens;
generating query data representing the first span data;
determining first entity data for the first span data by searching a memory layer using the query data;
determining second embedding data representing the first entity data by modifying the first entity data to have the same number of dimensions as the embedding space;
generating third embedding data by combining the first embedding data and the second embedding data;
determining named entity recognition (NER) tag data representing a predicted category of a portion of the first text data represented by the first span data, the NER tag data being generated using the third embedding data; and
determining, by an entity resolution (ER) component, an entity referred to by the utterance, the entity being associated with the predicted category.
|