| CPC G06F 18/2148 (2023.01) [G06F 16/383 (2019.01); G06F 40/295 (2020.01); G10L 15/26 (2013.01); G06F 2218/10 (2023.01)] | 20 Claims |
|
1. A computer system comprising:
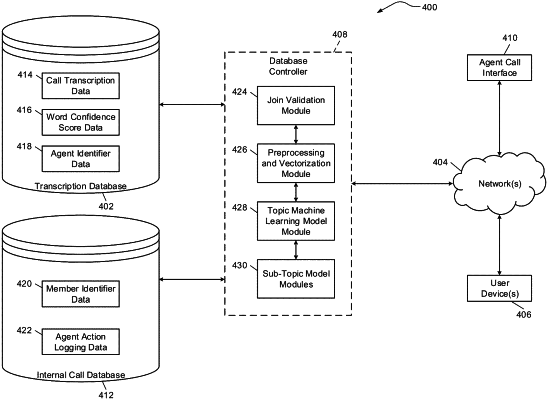
memory hardware configured to store a transcription database, a call database and computer-executable instructions, wherein the transcription database includes multiple call transcription data entries and multiple word confidence score data entries associated with each call transcription data entry, and wherein the call database includes multiple agent call log data entries; and
processor hardware configured to execute the instructions, wherein the instructions include:
joining at least a portion of the call transcription data entries with at least a portion of the agent call log data entries according to timestamps associated with the entries to generate a set of joined call data entries, wherein each of the set of joined call data entries includes one of the call transcription data entries paired with a corresponding one of the agent call log data entries;
for each of the set of joined call data entries:
obtaining a transcribed entity name from the call transcription data entry;
validating the joined call data entry by determining whether the transcribed entity name matches with entity identifier information associated with the agent call log data entry in satisfaction of a matching threshold indicative of a likelihood that the transcribed entity name and the entity identifier information refer to the same entity; and
in response to a successful validation of the joined call data entry:
preprocessing the joined call data entry according to the word confidence score data entries associated with the call transcription data entry to generate preprocessed text, wherein the preprocessing includes removing or replacing at least a portion of transcribed text of the call transcription data entry; and
performing natural language processing vectorization on the preprocessed text to generate an input vector for an unsupervised machine learning model; and
for each of at least a portion of the input vectors:
supplying the input vector to the unsupervised machine learning model to assign an output topic classification of the model to the joined call data entry associated with the input vector;
supplying the input vector to at least one sub-topic model associated with the output topic classification to assign one or more sub-topic output classifications to the joined call data entry associated with the input vector; and
modifying a user interface of a user device to display the output topic classification and the one or more sub-topic output classifications.
|