| CPC H04W 64/00 (2013.01) [G06N 3/08 (2013.01); H04W 84/12 (2013.01)] | 8 Claims |
|
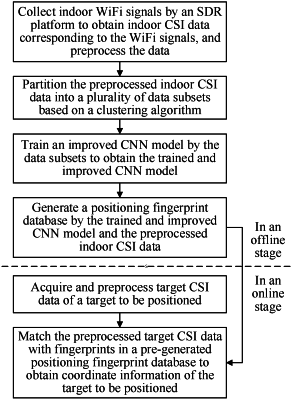
1. A method, comprising:
acquiring and preprocessing target camera serial interface (CSI) data of a to-be-positioned target; and
matching preprocessed target CSI data with fingerprints in a positioning fingerprint database to obtain coordinate information of the to-be-positioned target;
wherein:
a generation method of the positioning fingerprint database comprises:
collecting indoor WiFi signals by a software defined radio (SDR) platform to obtain indoor CSI data corresponding to the indoor WiFi signals, and preprocessing the indoor CSI data;
partitioning the preprocessed indoor CSI data into a plurality of data subsets through a clustering algorithm;
training an improved convolutional neural network (CNN) model by the plurality of data subsets to obtain a trained improved CNN model; and
generating the positioning fingerprint database by the trained improved CNN model and the preprocessed indoor CSI data;
wherein partitioning the preprocessed indoor CSI data into the plurality of data subsets through the clustering algorithm comprises:
dividing the preprocessed indoor CSI data into the plurality of data subsets by the clustering algorithm, and each data subset comprising a plurality of the indoor CSI data;
calculating a center of each data subset based on a k-means algorithm by following formula:
 where μi represents a center of an ith data subset, Ci represents the ith data subset, x represents the indoor CSI data i=1, . . . , k, where k is a number of data subsets;
calculating a square error of all data subsets based on the center of the ith data subset by following formula:
E=Σi=1kΣx∈Ci∥x−μi∥22 (2);
where E represents the square error of all data subsets; and
calculating a distance between the preprocessed indoor CSI data and the center of each data subset, re-partitioning the data subsets according to the distance until the square error is minimized, thereby obtaining a final data subset.
|