| CPC H04S 7/302 (2013.01) [H04R 5/02 (2013.01); H04S 3/008 (2013.01); H04S 2400/01 (2013.01); H04S 2400/11 (2013.01); H04S 2400/13 (2013.01)] | 20 Claims |
|
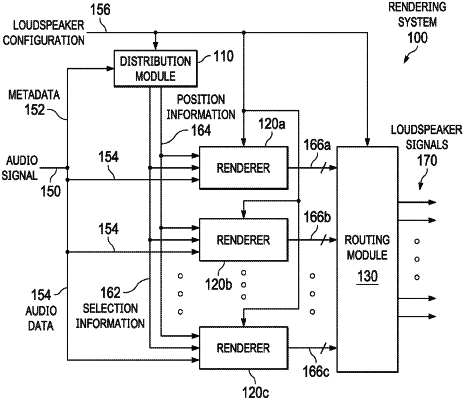
1. A method of audio processing, the method comprising:
receiving one or more audio objects, wherein each of the one or more audio objects respectively includes position information;
for a given audio object of the one or more audio objects:
selecting, based on the position information of the given audio object, at least two renderers of a plurality of renderers;
determining, based on the position information of the given audio object, at least two weights;
rendering, based on the position information, the given audio object using the at least two renderers weighted according to the at least two weights, to generate a plurality of rendered signals; and
combining the plurality of rendered signals to generate a plurality of loudspeaker signals; and
outputting, from a plurality of loudspeakers, the plurality of loudspeaker signals,
wherein the plurality of loudspeakers is arranged in a first group that is directed in a first direction and a second group that is directed in a second direction that differs from the first direction,
wherein the second direction includes a vertical component, wherein the at least two renderers include a wave field synthesis renderer, an upward firing panning renderer and a beamformer, and wherein the wave field synthesis renderer, the upward firing panning renderer and the beamformer generate the plurality of rendered signals for the second group.
|