| CPC H04L 12/1827 (2013.01) [G06V 10/507 (2022.01); G06V 40/20 (2022.01); H04L 12/1831 (2013.01)] | 19 Claims |
|
1. A method, comprising:
generating, by a transcription engine configured for automatic speech recognition, a real-time transcription of audio data from one or more participants temporally related to video data, wherein participants include a speaker participant and one or more audience participants;
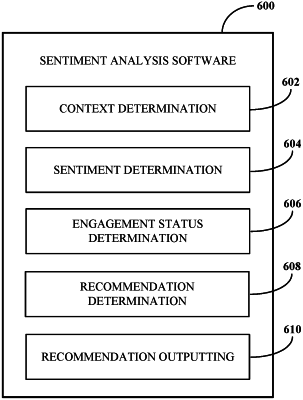
determining, by a processing of the video data using a machine learning system, meanings of reactions of the one or more audience participants to the speaker participant during a video conference based on the real-time transcription of the video conference and the reactions,
wherein the video data visually represents the reactions,
wherein determining the meanings of the reactions based on the real-time transcription of the video conference and the reactions includes determining a context associated with the speaker participant based on the real-time transcription of the video conference, and
wherein the context associated with the speaker participant relates to a purpose of the conference;
determining, by a server during the video conference, sentiment types of the one or more audience participants based on the determined meanings of the reactions, and maintaining a count of the determined sentiment types aggregated as bins in a histogram;
determining, by the server during the video conference, an engagement level based on the most frequent bin in the histogram;
causing, by the server, an outputting of a real-time recommendation based on the engagement level at a device associated with the speaker participant during the video conference; and
providing, by the server using the machine learning system, a real-time recommendation to the speaker participant based on real-time recommendations that were previously effective, which are determined based on an aggregation of engagement levels, real-time recommendations, and speaker participant behaviors over multiple conferences.
|