| CPC G10L 17/02 (2013.01) [G06F 16/90332 (2019.01); G10L 2015/088 (2013.01)] | 26 Claims |
|
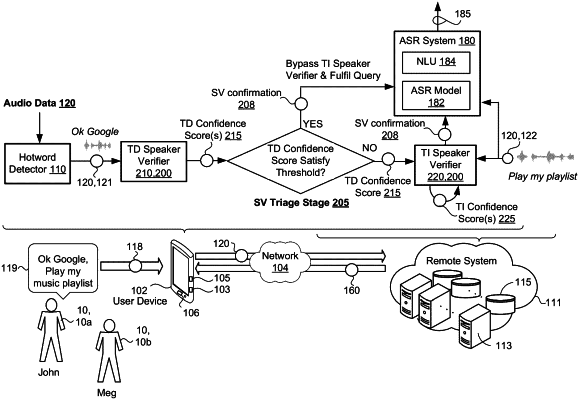
1. A computer-implemented method for speaker verification when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving audio data corresponding to an utterance captured by a user device, the utterance comprising a predetermined hotword followed by a query specifying an action to perform;
processing, using a text-dependent speaker verification (TD-SV) model, a first portion of the audio data that characterizes the predetermined hotword to generate a text-dependent evaluation vector representing voice characteristics of the utterance of the hotword;
generating one or more text-dependent confidence scores each indicating a likelihood that the text-dependent evaluation vector matches a respective one of one or more text-dependent reference vectors, each text-dependent reference vector associated with a respective one of one or more different enrolled users of the user device;
determining whether any of the one or more text-dependent confidence scores satisfy a confidence threshold; and one of:
when one of the text-dependent confidence scores satisfy the confidence threshold:
identifying a speaker of the utterance as the respective enrolled user that is associated with the text-dependent reference vector corresponding to the text-dependent confidence score that satisfies the confidence threshold; and
initiating performance of the action specified by the query without performing speaker verification on a second portion of the audio data that characterizes the query following the predetermined hotword; or
when none of the one or more text-dependent confidence scores satisfy the confidence threshold, providing an instruction to a text-independent speaker verifier, the instruction when received by the text-independent speaker verifier, causing the text-independent speaker verifier to:
process, using a text-independent speaker verification (TI-SV) model, the second portion of the audio data that characterizes the query to generate a text-independent evaluation vector, wherein the TI-SV model is more computationally intensive than the TD-SV model;
generate one or more text-independent confidence scores each indicating a likelihood that the text-independent evaluation vector matches a respective one of one or more text-independent reference vectors, each text-independent reference vector associated with a respective one of the one or more different enrolled users of the user device; and
determine, based on the one or more text-dependent confidence scores and the one or more text-independent confidence scores, whether the identity of the speaker that spoke the utterance includes any of the one or more different enrolled users of the user device,
wherein the data processing hardware resides on one of the user device or a distributed computing system in communication with the user device via a network, the data processing hardware executing both the TD-SV model and the TI-SV model.
|