| CPC G10L 17/00 (2013.01) [G10L 13/00 (2013.01); G10L 13/08 (2013.01); G10L 25/57 (2013.01); G10L 25/63 (2013.01)] | 12 Claims |
|
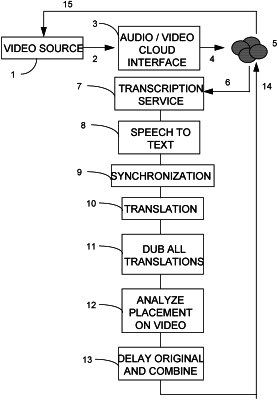
1. A system that performs dubbing automatically for multiple languages simultaneously using speech-to-text transcriptions and language translation comprising:
a. a first device that captures an original video program further comprising video image frames and synchronized audio speech by one or more speakers recorded in a source language;
b. a first transmitter that transmits the original video program;
c. a second device that processes the original video program and transmits it to a transcription service that
i. converts the synchronized audio speech to text strings, wherein each text string further comprises a plurality of words;
ii. determines the temporal start and end points for each of the plurality of words;
iii. from the temporal start and end points for each of the plurality of words, determines timing of pauses between each of the plurality of words;
iv. from the timing of the pauses, determines which words in each text string form phrases and which words in each text string form sentences;
v. assigns temporal anchors to each phrase and sentence;
vi. assigns parameters to each word, phrase and sentence, wherein said parameters determine:
a speaker identifier;
a gender of the speaker;
whether the speaker is an adult or a child;
an inflection and emphasis of each word in the phrase;
a volume of each word in the phrase;
a tonality of each word in the phrase;
a raspness of each word in the phrase; and
an emotional indicator for the phrase,
wherein the speaker identifier and the emotional indicator are each determined using artificial intelligence;
vii. synchronizes the assigned parameters of each word, phrase and sentence using the temporal anchors within each text string;
d. a translation engine that produces a plurality of text scripts in various target languages from each phrase, wherein each of plurality of text scripts contains a series of concatenated text strings along with associated inflection, tonality, emphasis, raspness, emotional indication, and volume indicators as well as timing and speaker identifiers for each word, phrase, and sentence that is derived from the synchronized audio speech recorded in the source language;
e. a dubbing engine that creates audio strings in the various target languages that are time synchronized to their source language audio strings by utilizing the temporal anchors;
f. an analysis module that analyzes the optional placement and superposition of subtitles comprising the text strings in either the source language or the various target languages onto the original video program, wherein the analysis of the optional placement and the superposition of the subtitles is performed using artificial intelligence; and
g. a second transmitter that transmits the original video program containing the created audio strings in the various target languages, and which may also optionally comprise the subtitles.
|