| CPC G10L 15/26 (2013.01) [G10L 15/16 (2013.01); G10L 15/193 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01)] | 19 Claims |
|
15. A computing system comprising:
one or more processing devices; and
one or more storage devices storing instructions that, when executed by the one or more processing devices, cause the one or more processing devices to perform operations comprising:
generating a text representation of audio data capturing a spoken utterance, including an alphanumeric sequence, using an automatic speech recognition (“ASR”) engine, wherein generating the text representation of the audio data capturing the spoken utterance, including the alphanumeric sequence, using the ASR engine, comprises:
determining contextual information for the alphanumeric sequence;
selecting, based on the contextual information, one or more contextual finite state transducers for the alphanumeric sequence;
generating a set of candidate recognitions of the spoken utterance based on processing the audio data using an ASR model portion of the ASR engine; and
generating the text representation of the spoken utterance, wherein the text representation includes the alphanumeric sequence, and wherein generating the text representation is based on the generated set of candidate recognitions and the one or more selected contextual finite state transducers;
generating at least a given contextual finite state transducer, of the one or more contextual finite state transducers, wherein generating the given contextual finite state transducer comprises:
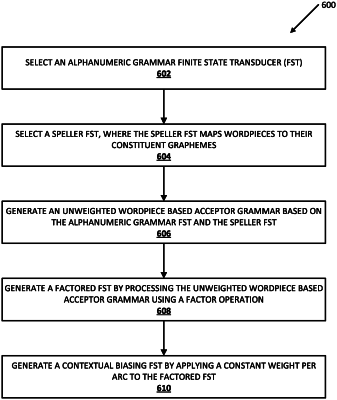
selecting an alphanumeric grammar finite state transducer corresponding to the alphanumeric sequence;
selecting a speller finite state transducer which maps wordpieces to constitute graphemes;
generating an unweighted wordpiece based acceptor grammar based on the alphanumeric grammar finite state transducer and the speller finite state transducer;
generating a factored finite state transducer based on processing the unweighted wordpiece based acceptor grammar using a factor operation; and
generating the given contextual finite state transducer based on applying a constant weight to each arc in the unweighted wordpiece based acceptor grammar.
|