| CPC G10L 15/20 (2013.01) [G06F 16/316 (2019.01); G06F 40/289 (2020.01); G10L 15/10 (2013.01); G10L 15/26 (2013.01); G10L 15/285 (2013.01); G10L 17/04 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
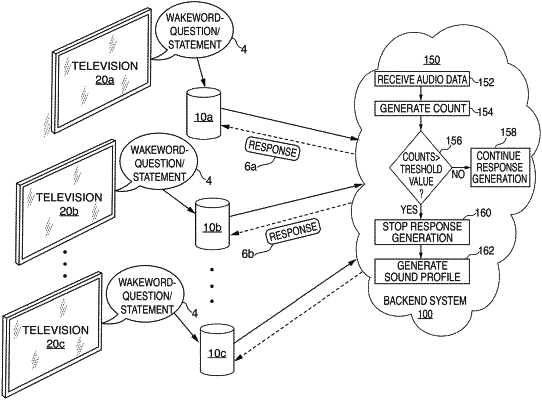
1. A computer-implemented method, comprising:
receiving first audio data representing first speech output by a device;
determining that the first audio data corresponds to a stored sound profile;
after determining that the first audio data corresponds to the stored sound profile, receiving second audio data representing second speech, the second audio data including a representation of a wakeword; and
performing at least one action with respect to the second audio data based at least in part on the first audio data having corresponded to the stored sound profile.
|