| CPC G10L 15/1815 (2013.01) [G10L 15/22 (2013.01); G10L 15/063 (2013.01)] | 20 Claims |
|
1. A system comprising:
a computing device configured to:
receive an audio data representation of an utterance from a user;
detect a plurality of words within the utterance based on the audio data representation;
contextualize each of the plurality of words;
provide each contextualized word of the plurality of words to a slot detector, a slot classifier, and an intent classifier;
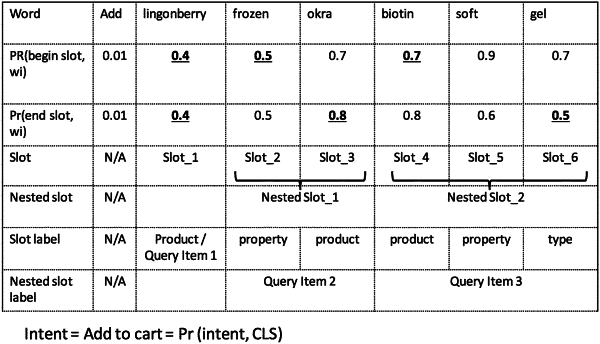
determine one or more slots in the utterance using the slot detector, each slot being a portion of the utterance, wherein the one or more slots are determined based on:
determining a first probability of each contextualized word in the utterance being a beginning word of a slot,
determining a second probability of each contextualized word in the utterance being an end word of a slot, and
determining word boundaries of the one or more slots in the utterance based on all of the first probabilities and the second probabilities,
wherein the word boundaries divide the utterance into the one or more slots;
determine one or more slot classifications of the one or more slots using the slot classifier;
determine an intent using the intent classifier; and
provide an output based on the determined intent, one or more slots, and one or more slot classifications.
|