| CPC G10L 13/02 (2013.01) [G06N 3/08 (2013.01); G10L 15/18 (2013.01); G10L 25/30 (2013.01); G10L 25/51 (2013.01)] | 20 Claims |
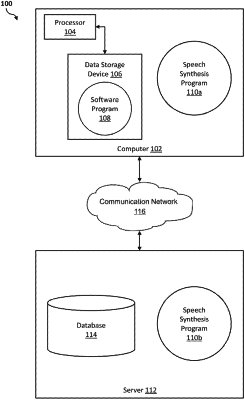
|
1. A method for speech synthesis, the method comprising:
generating one or more final voiceprints by adjusting one or more initial voiceprints using a generative adversarial network;
generating one or more voice clones based on the one or more final voiceprints;
classifying the one or more voice clones into a grouping using a language model, wherein the grouping is comprised of at least two or more subgroupings based on a multi-class classification performed by the language model using corresponding vectors, and wherein the two or more subgroupings are added as classifications to a speech corpus;
identifying a cluster within the grouping, wherein the cluster is identified by determining a difference between corresponding vectors of the one or more voice clones below a similarity threshold;
generating a new archetypal voice by blending the one or more voice clones of the cluster where the difference between the corresponding vectors is below the similarity threshold, wherein the new archetypal voice is labeled utilizing identifying information embedded in the one or more final voiceprints corresponding to the one or more voice clones below the similarity threshold; and
generating a personalized archetypal voice by blending the new archetypal voice and at least one other archetypal voice selected by a user from the speech corpus using a display, wherein the display includes a plurality of labeled archetypal voices available to the user for blending.
|