| CPC G06V 10/806 (2022.01) [G06V 10/82 (2022.01); G06V 20/46 (2022.01)] | 10 Claims |
|
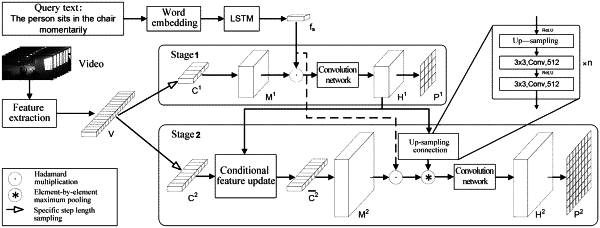
1. A progressive localization method for text-to-video clip localization, comprising:
step 1: extracting a video feature and a text feature, respectively, by using different feature extraction methods;
step 2: coarse-time-granularity localization: sampling the video feature obtained in step 1 with a first step length to generate a candidate clip;
step 3: fusing the candidate clip obtained in step 2 with the text feature obtained in step 1;
step 4: feeding the fused feature to a convolution neural network to obtain a coarse-grained feature map, and then obtaining a correlation score map via an fully-connected (FC) layer;
step 5: fine-time-granularity localization: sampling the video feature obtained in step 1 with a second step size, updating the features by a conditional feature update module by combining with the feature map obtained in step (4), and then generating a candidate clip, wherein the first step is greater than the second step;
step 6: fusing the candidate clip in step 5 with the text features obtained in step 1, and fusing the candidate clip in step 5 by combining the feature map obtained in step 4 through up-sampling connection;
step 7: feeding the fused features to the convolution neural network to obtain a fine-grained feature map, and then obtaining a correlation score map by an FC layer;
step 8: calculating a loss value of the correlation score matrices obtained in step 4 and step 7 by using binary cross entropy loss, respectively, combining the loss value with a certain weight, and finally training a model in an end-to-end manner; and
step 9: realizing text-based video clip localization by using the model trained in step 8.
|