| CPC G06V 10/774 (2022.01) [G06N 3/045 (2023.01); G06N 3/047 (2023.01)] | 20 Claims |
|
1. A method performed by one or more data processing apparatus for training a classification neural network, the method comprising:
for each of a plurality of network inputs:
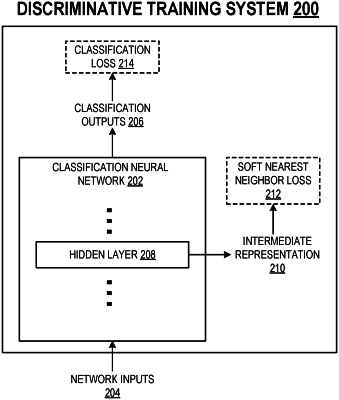
processing the network input using the classification neural network, in accordance with current values of classification neural network parameters, to generate a classification output that defines a predicted class of the network input;
determining a soft nearest neighbor loss based on, for each of a plurality of pairs of network inputs that comprise a first network input and a second network input from the plurality of network inputs, a respective measure of similarity between:
(i) an intermediate representation of the first network input that is generated by one or more hidden layers of the classification neural network by processing the first network input to generate the classification output for the first network input, and
(ii) an intermediate representation of the second network input that is generated by one or more hidden layers of the classification neural network by processing the second network input to generate the classification output for the second network input;
wherein the soft nearest neighbor loss encourages intermediate representations of network inputs of different classes to become more entangled, wherein the entanglement of intermediate representations of network inputs of different classes characterizes how similar pairs of intermediate representations of network inputs of different class are relative to pairs of intermediate representations of network inputs of the same class; and
adjusting the current values of the classification neural network parameters using gradients of the soft nearest neighbor loss with respect to the classification neural network parameters.
|