| CPC G06Q 40/123 (2013.12) [G06N 20/00 (2019.01); G06V 30/19167 (2022.01); G06V 30/19173 (2022.01); G06V 30/412 (2022.01); G06V 30/10 (2022.01)] | 16 Claims |
|
12. A method for summarizing tax documents that include an unstructured portion, the method comprising:
receiving a tax document that includes a structured facepage portion and an unstructured free form whitepaper portion;
identifying which portion of the tax document is the structured facepage portion and which portion is the unstructured whitepaper portion;
extracting a plurality of structured data elements from the structured facepage portion;
extracting, using a machine learning model, a plurality of unstructured data elements from the unstructured free form whitepaper portion, wherein the machine learning model is configured to target extraction of specific data elements from the unstructured free form whitepaper portion related to one or more of state apportionment, unrelated business taxable income(“UBTI”) data, and/or foreign disclosures from the whitepaper portion of the tax document;
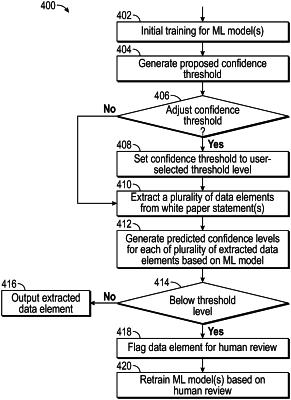
generating, using a machine learning model, a confidence level associated with each extracted unstructured data element, wherein the confidence level represents a prediction on how likely the extracted unstructured data element was accurately extracted;
generating a document in an electronic interchange format that represents: (i) the plurality of extracted structured data elements from the structured facepage portion; (ii) the plurality of extracted unstructured data elements from the unstructured whitepaper portion; and (iii) the confidence level associated with each of the plurality of extracted unstructured data elements;
establishing a confidence level threshold and flag any extracted unstructured data elements with an associated confidence level below the confidence level threshold, wherein the confidence level threshold is user-adjustable;
adjusting one or more parameters of the machine learning model by: (i) training and/or re-training the machine learning model based on historical data extractions; (ii) generating, based on the training or re-training, a proposed threshold confidence level as to whether extracted data elements were correctly extracted; (iii) determining whether a user would like to adjust the confidence level; and (iv) adjusting the confidence level to a user-selected threshold level; and
wherein the plurality of extracted unstructured data elements in the electronic interchange format are organized into a data schema with: (1) one or more top-level fields including a form year, an entity name, an investor name or a filing date; (2) an array of data corresponding to one or more parts of the tax document; and (3) additional extracted fields including (a) state apportionment data, (b) unrelated business taxable income(“UBTI”) data, and/or (c) foreign disclosures data.
|