| CPC G06Q 30/0275 (2013.01) [G06N 3/045 (2023.01); G06N 3/084 (2013.01); G06Q 30/0246 (2013.01); G06Q 30/0205 (2013.01); G06Q 30/0249 (2013.01); G06Q 30/0256 (2013.01); G06Q 30/0276 (2013.01)] | 20 Claims |
|
1. A machine learning system comprising:
one or more processors; and
a memory storing instructions that, when executed by at least one processor in the one or more processors, cause the at least one processor to perform operations comprising at least:
receive a request to deploy a piece of content to available inventory;
receive a bid result for a bid on the available inventory, the bid submitted to a real time bid server in response to the request;
store state data including a sequence of bids sent to the real time bid server, the bid result, and a response rate for the available inventory;
train a bidding model by:
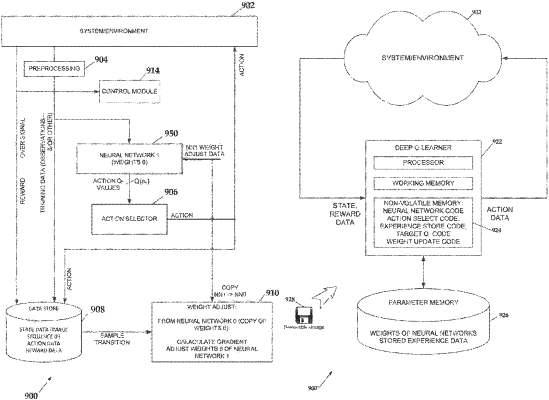
using a first neural network, determining a plurality of action Q-values based on the state data, the plurality of action Q-values including at least one Q-value for each possible action at a current state of the bid server;
selecting an action based on a maximum action Q-value;
using a second machine learning model, determining a target Q-value for the selected action based on the state data and experience data, the experience data including the selected action and a reward earned for the selected action;
training the first neural network to update the plurality of action Q-values based on the target Q-value, the training using a stochastic gradient descent;
determine a bid action using the trained bidding model; and
submit a new bid on the available inventory to the real time bid server based on the bid action.
|