| CPC G06N 5/04 (2013.01) [G06F 17/16 (2013.01); G06F 18/2113 (2023.01); G06F 18/2193 (2023.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
obtaining a performance matrix representing accuracies obtained by executing a plurality of machine-learning pipelines on a plurality of training data sets, wherein a machine-learning pipeline comprises a series of operations performed on a data set;
selecting a defined number of top machine-learning pipelines as potential machine-learning pipelines for a testing data set based, at least in part, on computing a similarity between the testing data set and each of the plurality of training data sets represented in the performance matrix;
determining a pipeline accuracy for each of the potential machine-learning pipelines when executed against the testing data set;
providing a recommended machine-learning pipeline for use with the testing data set based, at least in part, on the pipeline accuracy for each potential machine-learning pipeline; and
performing initialization for pipeline recommendation prior to the computing of similarities between the testing data set and each of the plurality of training data sets represented in the performance matrix, the initialization comprising:
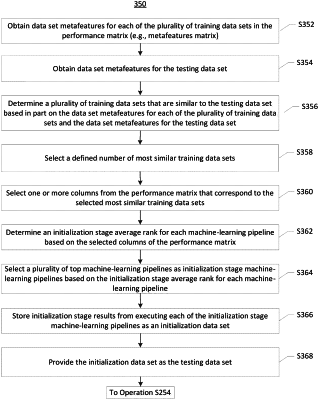
obtaining data set metafeatures for each of the plurality of training data sets in the performance matrix;
obtaining data set metafeatures for the testing data set;
determining a plurality of similar training data sets that are similar to the testing data set based in part on the data set metafeatures for each of the plurality of training data sets and the data set metafeatures for the testing data set;
selecting a defined number of most similar training data sets;
selecting one or more columns from the performance matrix that correspond to the selected most similar training data sets;
determining an initialization stage average rank for each machine-learning pipeline based on the selected columns of the performance matrix;
selecting a plurality of top machine-learning pipelines as initialization stage machine-learning pipelines based on the initialization stage average rank for each machine-learning pipeline;
storing initialization stage results from executing each of the initialization stage machine-learning pipelines as an initialization data set; and
providing the initialization data set as the testing data set;
storing results from executing each of the potential machine-learning pipelines as a new data set.
|