| CPC G06N 3/08 (2013.01) [G06F 16/29 (2019.01); G06N 7/01 (2023.01)] | 9 Claims |
|
1. An address information feature extraction method based on a deep neural network model, the method comprising steps of:
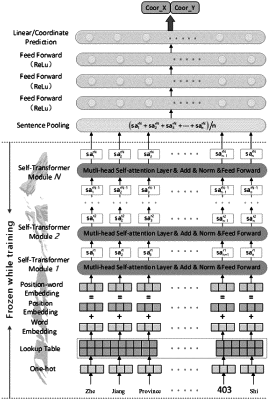
S1: constructing a word embedding module weighted by a position order, for expressing, through a position coding algorithm and a built-in matrix variable, each address character in an input address text in a form of a unique-value vector, to achieve conversion of address information from text to code;
S2: constructing a feature extraction module for character encoding, and obtaining, through a semantic extraction method of a multi-head self-attention mechanism, a comprehensive semantic output of a character element in different semantic spaces;
S3: constructing a target task module that predicts unknown characters based on context, and outputting, under a condition of satisfying that the address character and the context represent a mapping relationship, a conditional probability distribution of predicted characters required by the training task;
S4: connecting the word embedding module in the step S1, the feature extraction module in the step S2 and the target task module in the step S3 in sequence, to form a Chinese addresses language model, and training the Chinese addresses language model using a natural language training program based on a random masking strategy, such that the model outputs and obtains a semantic feature vector of each character in the address text;
S5: synthesizing the semantic feature vectors of all the characters in the address text, obtaining a sentence vector through a pooling method of the address semantic features, performing high-dimensional weighting in combination with geospatial position information, and obtaining a semantic-geospatial fusion clustering result through a K-Means clustering method;
S6: transplanting the word embedding module and the feature extraction module in the Chinese addresses language model trained and completed in the step S4, to form an encoder; reconstructing, based on a neural network fine-tuning theory, the target task module, to form a decoder, for using the clustering result in the step S5 as an address text label, to assign a semantic-geospatial fusion weight to a neural network parameter variable in the encoder; and
S7: combining the encoder and the decoder to construct a geospatial-semantic address model, and training the geospatial-semantic address model, such that the model can output the fusion vector expression of the semantic and geospatial features for the address text,
wherein in the step S2, a specific execution flowchart in the feature extraction module comprises steps of:
S21: inputting a character vectorization expression content output by the word embedding module in the step S1 into a neural network formed by series connection of multiple layers of self-transformer sub-modules; in each layer of the self-transformer sub-module, input data is first substituted into a self-attention neural network, output thereof undergoes a residual and normalization calculation and then is substituted into a feed forward network layer, and then undergoes another residual and normalization calculation and then serves as output of the self-transformer sub-module; and
S22: in other layer of self-transformer sub-modules except a first layer of self-transformer sub-module, output of a previous layer of self-transformer sub-module serving as input of a next layer of self-transformer sub-module, transferring layer by layer, until output SAN of the last layer of self-transformer sub-module is obtained.
|