| CPC G06N 3/08 (2013.01) [G06N 3/04 (2013.01); G06N 3/10 (2013.01)] | 18 Claims |
|
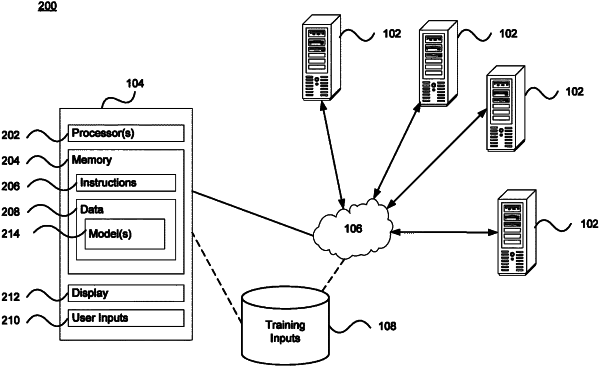
1. A method for training a model on a distributed system, comprising:
automatically selecting, by the distributed system based on one or more attributes, a first subset of processors among a plurality of available processors located on a plurality of computing devices of the distributed system to train the model, the processors in the first subset each being configured to handle a threshold amount of simultaneous processing threads and having the one or more attributes;
automatically selecting, by the distributed system, a second subset of processors among the plurality of available processors to aggregate training results, the processors in the second subset each having a threshold amount of memory for aggregation;
generating, by the distributed system, a copy of the model on each of the first subset of processors, the generating including applying one or more perturbations to an input of the copy of the model, each copy of the model having an identifier associated therewith, the identifiers being used to track how each copy of the model is trained, to track the training results of one copy of the model relative to other copies of the model in order to evaluate different types of training behavior, to augment the training results based on a real world scenario, and to weigh the training results based on a desired distribution, each copy of the model being configured to work on one or more different types of data associated with the model;
training, by the distributed system, the copies of the model on the first subset of processors; and
aggregating, by the distributed system based on the identifiers and the training results, the trained copies of the model on the second subset of processors.
|