| CPC G06N 3/008 (2013.01) [B25J 9/161 (2013.01); B25J 9/162 (2013.01); B25J 9/163 (2013.01); B25J 9/1697 (2013.01); B25J 13/08 (2013.01); G05B 13/027 (2013.01); G05D 1/0221 (2013.01); G06F 18/21 (2023.01); G06N 3/044 (2023.01); G06T 7/593 (2017.01); G06V 20/10 (2022.01); G06V 30/274 (2022.01); G10L 15/16 (2013.01); G10L 15/1815 (2013.01); G10L 15/22 (2013.01); G10L 25/78 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A method implemented by one or more processors, comprising:
receiving an instance of vision data, the instance of vision data generated based on output from one or more vision sensors of a vision component of a robot, and the instance of vision data capturing at least part of an environment of the robot;
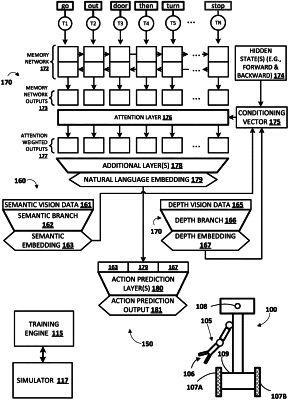
generating at least one vision embedding using at least one vision branch of a neural network model, wherein generating the at least one vision embedding comprises:
generating semantic vision data, wherein generating the semantic vision data is based on processing at least some of the instance of vision data using one or more additional neural networks, and wherein the semantic vision data includes natural language labels of objects captured in the at least some of the instance of vision data, and
generating a semantic embedding of the at least one vision embedding, wherein generating the semantic embedding is based on processing the semantic vision data using a semantic vision branch of the at least one vision branch of the neural network model;
receiving free-form natural language input, the free-form natural language input generated based on user interface input provided by a user via one or more user interface input devices;
generating a natural language embedding based on processing the free-form natural language input using a language branch of the neural network model;
generating an action prediction output based on processing of the at least one vision embedding and the natural language embedding using action prediction layers of the neural network model, wherein the action prediction output indicates a robotic action to be performed based on the instance of vision data and the free-form natural language input; and
controlling one or more actuators of a robot based on the action prediction output, wherein controlling the one or more actuators of the robot causes the robot to perform the robotic action indicated by the action prediction output.
|