| CPC G06N 20/20 (2019.01) [G06F 18/21375 (2023.01); G06F 18/2148 (2023.01); G06F 18/2185 (2023.01); G06F 18/2433 (2023.01); G06N 5/01 (2023.01); G06N 7/01 (2023.01); G06N 20/00 (2019.01)] | 30 Claims |
|
1. A system comprising one or more processors, and at least one memory comprising computer program code, the at least one memory and the computer program code configured to, with the one or more processors, cause the system to:
receive a plurality of data records from a data source, each data record of the plurality of data records comprising a feature vector comprising (i) a plurality of predictor variables and (ii) a plurality of corresponding predictor variable values;
for each data record of the plurality of data records,
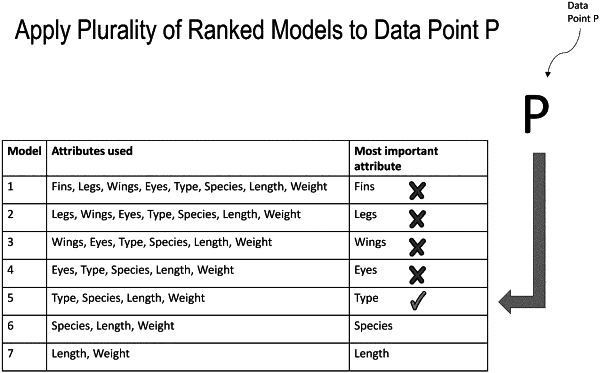
apply a first machine learning model that is trained with a true data set and an adversarial data set to the data record to generate an output that represents a probability that the data record belongs to a distribution represented by the true data set; and
responsive to determining that the output is not a first successful output, sequentially apply one or more subsequent machine learning models of a plurality of subsequent machine learning models to the data record until a second successful output is obtained, wherein (i) the one or more subsequent machine learning models are iteratively generated based on an updated true data set and an updated adversarial data set, (ii) the updated true data set is without a true data set column, (iii) the updated adversarial data set is without an adversarial data set column, and (iv) the true data set column and the adversarial data set column are associated with a predictive variable of an immediately preceding subsequent machine learning model having a highest feature importance for distinguishing the true data set from the adversarial data set; and
output an indication that the plurality of data records contains at least one anomalous data record based at least in part on the second successful output.
|