| CPC G06F 8/443 (2013.01) [G06F 8/427 (2013.01)] | 20 Claims |
|
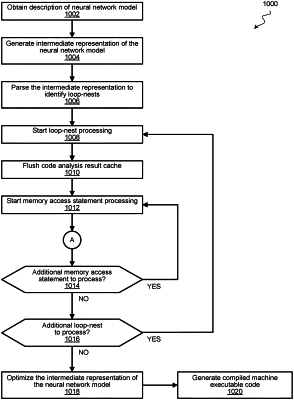
1. A computer-implemented method for compiling a neural network model, the method comprising:
obtaining a description of the neural network model;
generating an intermediate representation of the neural network model;
parsing the intermediate representation to identify loop-nest constructs;
for each of the loop-nest constructs:
flushing a code analysis result cache; and
for each memory access statement in the loop-nest construct:
generating a lookup key from control statements bounding the memory access statement;
determining whether the lookup key is stored in an entry of the code analysis result cache;
if the lookup key results in a cache miss:
performing an affine analysis on the memory access statement to generate an affine analysis result for the memory access statement, the affine analysis result indicating a set of execution conditions for the memory access statement;
storing the affine analysis result with the lookup key in the code analysis result cache; and
modifying the memory access statement according to the affine analysis result; and
if the lookup key results in a cache hit:
retrieving a cached affine analysis result associated with the lookup key from the code analysis result cache; and
modifying the memory access statement according to the cached affine analysis result;
optimizing the intermediate representation of the neural network model based on the modified memory access statement; and
compiling the optimized intermediate representation of the neural network model into machine executable code.
|