| CPC G06F 40/35 (2020.01) [G06F 40/284 (2020.01); G06N 3/049 (2013.01)] | 10 Claims |
|
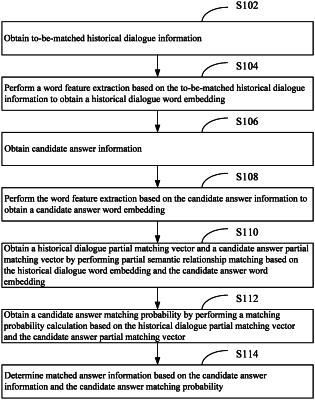
1. A context-based multi-turn dialogue method, comprising steps of:
obtaining to-be-matched historical dialogue information;
performing a word feature extraction based on the to-be-matched historical dialogue information to obtain a historical dialogue word embedding;
obtaining candidate answer information;
performing the word feature extraction based on the candidate answer information to obtain a candidate answer word embedding;
obtaining a historical dialogue partial matching vector and a candidate answer partial matching vector by performing partial semantic relationship matching based on the historical dialogue word embedding and the candidate answer word embedding;
obtaining a candidate answer matching probability by performing a matching probability calculation based on the historical dialogue partial matching vector and the candidate answer partial matching vector; and
determining matched answer information based on the candidate answer information and the candidate answer matching probability;
wherein the step of performing the word feature extraction based on the to-be-matched historical dialogue information to obtain the historical dialogue word embedding comprises:
performing a token extraction on the to-be-matched historical dialogue information to obtain a to-be-predicted historical dialogue token; and
inputting the to-be-predicted historical dialogue token into a pre-trained model for prediction to obtain the historical dialogue word embedding with contextual meaning;
wherein the step of performing the token extraction on the to-be-matched historical dialogue information to obtain the to-be-predicted historical dialogue token comprises:
generating a historical dialogue sequence by inserting at least one of sentence breaks and turn breaks to the to-be-matched historical dialogue information;
performing a word segmentation on the historical dialogue sequence to obtain a to-be-processed historical dialogue token;
extracting the to-be-processed historical dialogue token according to a preset historical dialogue length to obtain a standard historical dialogue token; and
inserting a first classifier at a beginning of the standard historical dialogue token and a first separator at an end of the standard historical dialogue token to obtain the to-be-predicted historical dialogue token;
wherein the step of extracting the to-be-processed historical dialogue token according to the preset historical dialogue length to obtain the standard historical dialogue token comprises:
obtaining the preset historical dialogue length;
deleting tokens from a beginning of the to-be-processed historical dialogue token in response to the number of the tokens in the to-be-processed historical dialogue token being larger than the preset historical dialogue length, until the number of the tokens in the to-be-processed historical dialogue token is equal to the preset historical dialogue length, and using the other tokens remaining in the to-be-processed historical dialogue token as the standard historical dialogue token; and
using the to-be-processed historical dialogue token as the standard historical dialogue token in response to the number of the tokens in the to-be-processed historical dialogue token being less than or equal to the preset historical dialogue length;
wherein the step of performing the word feature extraction based on the candidate answer information to obtain the candidate answer word embedding comprises:
performing the token extraction on the candidate answer information to obtain a to-be-predicted candidate answer token; and
inputting the to-be-predicted candidate answer token into the pre-trained model for prediction to obtain the candidate answer word embedding with the contextual meaning;
wherein the pre-trained model is a word feature extraction neural network model, the word feature extraction neural network model uses a transformer as a framework of an algorithm, and uses a masked language prediction and a next sentence prediction to perform a pre-training; and
wherein the masked language prediction and the next sentence prediction are unsupervised prediction tasks; and
wherein the step of performing the token extraction on the candidate answer information to obtain the to-be-predicted candidate answer token comprises:
performing a word segmentation on the candidate answer information to obtain a to-be-processed candidate answer token;
extracting the to-be-processed candidate answer token according to a preset candidate answer length to obtain a standard candidate answer token; and
inserting a second classifier at a beginning of the standard candidate answer token and inserting a second separator at an end of the standard candidate answer token to obtain the to-be-predicted candidate answer token;
wherein the step of extracting the to-be-processed candidate answer token according to the preset candidate answer length to obtain the standard candidate answer token comprises:
obtaining the preset candidate answer length;
deleting tokens from the end of the to-be-processed candidate answer token in response to the number of the tokens in the to-be-processed candidate answer token being larger than the preset candidate answer length, until the number of the tokens in the to-be-processed candidate answer tokens is equal to the preset candidate answer length, and using the other tokens remained remaining in the to-be-processed candidate answer token as the standard candidate answer token; and
using the to-be-processed candidate answer token as the standard candidate answer token in response to the number of the tokens in the to-be-processed candidate answer tokens being less than or equal to the preset candidate answer length; and
wherein the step of obtaining the candidate answer matching probability by performing the matching probability calculation based on the historical dialogue partial matching vector and the candidate answer partial matching vector comprises:
inputting the historical dialogue partial matching vector into a BiLSTM layer for key vector identification to obtain a historical dialogue hidden vector;
inputting the candidate answer partial matching vector into the BiLSTM layer for key vector identification to obtain a candidate answer hidden vector;
performing a max pooling on each of the historical dialogue hidden vector and the candidate answer hidden vector to obtain a historical dialogue max pooling vector and a candidate answer max pooling vector, respectively;
performing an average pooling on each of the historical dialogue hidden vector and the candidate answer hidden vector to obtain a historical dialogue average pooling vector and a candidate answer average pooling vector, respectively; and
performing a matching probability calculation based on the historical dialog max pooling vector, the historical dialog average pooling vector, the candidate answer max pooling vector, and the candidate answer average pooling vector to obtain the candidate answer matching probability.
|