| CPC G06F 40/295 (2020.01) [G06F 40/274 (2020.01); G06N 3/049 (2013.01)] | 13 Claims |
|
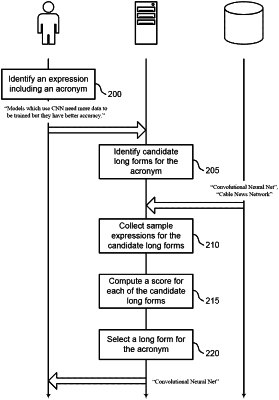
1. A method for natural language processing, comprising:
receiving a prompt comprising an input sequence including a short form;
encoding a plurality of words from the input sequence to obtain a first representation vector by computing a plurality of word embeddings corresponding to the plurality of words, respectively, and generating the first representation vector based on the plurality of word embeddings;
encoding the short form to obtain a second representation vector;
generating an input sequence representation based on the first representation vector and the second representation vector using a neural network that is trained based on ground-truth long form data;
encoding each of a plurality of candidate long forms to produce a plurality of candidate long form representations, wherein each of the candidate long form representations is based on a plurality of sample expressions and each of the sample expressions includes a candidate long form and contextual information;
computing a plurality of similarity scores for each of the candidate long forms based on the plurality of candidate long form representations, respectively, wherein the plurality of similarity scores include a first similarity score and a second similarity score, wherein the first similarity score is based on the plurality of word embeddings and at least one of the candidate long form representations, and wherein the second similarity score is based on the input sequence representation and the at least one of the candidate long form representations;
computing a weighted sum of the first similarity score and the second similarity score; and
generating a response to the prompt including a long form corresponding to the short form based on the weighted sum.
|