| CPC G06F 40/20 (2020.01) [G06N 3/045 (2023.01); G10L 15/16 (2013.01)] | 18 Claims |
|
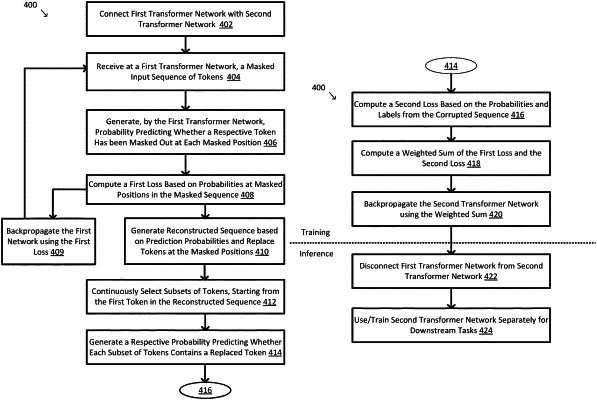
1. A system for pre-training a transformer network, the system comprising:
a first transformer network including a first plurality of transformer layers,
wherein at least a first transformer layer in the first transformer network receives inputs from all preceding transformer layers of the at least first transformer layer in the first transformer network, and an output of the at least first transformer layer is sent to all subsequent transformer layers of the at least first transformer layer in the first transformer network, and
wherein the first transformer network receives a masked input sequence of tokens and outputs a first reconstructed sequence with alternative tokens that replace the masked-out tokens; and
a second transformer network including a second plurality of transformer layers,
wherein at least a second transformer layer in the second transformer network receives inputs from all preceding transformer layers of the at least second transformer layer in the second transformer network, and an output of the at least second transformer layer is sent to all subsequent transformer layers of the at least second transformer layer in the second transformer network,
wherein the second transformer network receives the first reconstructed sequence of tokens containing the alternative tokens from the first transformer network and predicts whether a subset of tokens from the first reconstructed sequence contains a replaced token, and
wherein the second transformer network further selects the subset of tokens having a pre-defined length from the first reconstructed sequence, and generates a probability predicting whether the subset of tokens contains a replaced token.
|