| CPC G06F 21/6218 (2013.01) [G06F 16/2282 (2019.01); G06F 16/24578 (2019.01); G06F 16/285 (2019.01)] | 12 Claims |
|
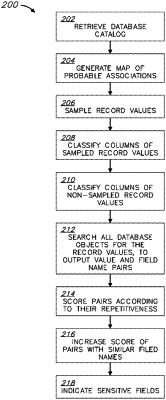
1. A method for automated sensitive data classification, the method comprising:
retrieving a catalog of a database, wherein the catalog comprises metadata defining objects of the database, wherein the objects include tables and columns;
sampling record values from at least some of the columns, wherein the sampling comprises ignoring record values selected from a group consisting of: null, blank, zero, Boolean, and strings shorter than a predefined length, and further comprises removing at least one of a prefix and a suffix from the sampled record values through use of a spelling suggestion algorithm;
generating a map of probable associations between different columns of the tables of the database, based on: (a) the metadata, and (b) the sampled record values;
applying a machine learning classifier to the sampled record values, to classify the columns of the sampled records into multiple data classes, wherein at least some of the data classes are sensitive data classes;
classifying columns of non-sampled record values according to the classification of the sampled record values, based on the map of probable associations between the different columns;
searching all objects of the database for existence of record values of the classified columns, to output value and field name pairs;
scoring the pairs according to a measure of their repetitiveness in the output, wherein the score corresponds to a count of pieces of data, and wherein a higher repetitiveness produces a higher score and a lower repetitiveness produces a lower score;
increasing the scores of the pairs whose field names are similar, wherein the field names are determined to be similar using at least one of: a stemming algorithm and a natural-language understanding (NLU) algorithm; and
based on the scores of the pairs, indicating which fields of the database are likely to include sensitive data.
|