| CPC G06F 18/2431 (2023.01) [G06V 10/44 (2022.01); G06V 20/80 (2022.01); G06V 30/194 (2022.01); G06V 30/413 (2022.01)] | 20 Claims |
|
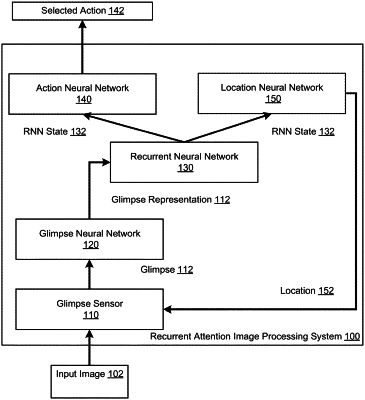
1. A method for processing one or more images of an environment to select an action to be performed by an agent interacting with the environment, the method comprising:
at each iteration of a plurality of iterations:
receiving a current image for the iteration, wherein the current image is included in the one or more images;
determining a location in the current image, comprising:
determining the location based on an output of a location neural network for the current iteration if the current iteration is after a first iteration in the plurality of iterations;
extracting a glimpse from the current image using the location;
updating a current internal state of a recurrent neural network using the glimpse extracted from the current image to generate a new internal state, comprising:
generating a glimpse representation of the extracted glimpse, and
processing the glimpse representation using the recurrent neural network to update the current internal state of the recurrent neural network to generate a new internal state;
processing, using the location neural network, the new internal state of the recurrent neural network generated using the glimpse extracted from the image to generate an output of the location neural network for a next iteration in the plurality of iterations; and
at a last iteration of the plurality of iterations, selecting the action to be performed by the agent, including:
processing, using an action neural network, the new internal state of the recurrent neural network at the last iteration to generate a respective action score for each action in a set of actions; and
selecting the action to be performed by the agent using the action scores;
wherein the location neural network, the recurrent neural network, and the action neural network have been trained by an end-to-end optimization procedure.
|