| CPC G06F 18/2155 (2023.01) [G06N 20/00 (2019.01); G06T 7/20 (2013.01); G06V 20/46 (2022.01); G06V 20/49 (2022.01); G06T 2207/10016 (2013.01); G06T 2207/20081 (2013.01)] | 20 Claims |
|
1. A system comprising:
one or more processors; and
one or more memories including program code that is executable by the one or more processors for causing the one or more processors to:
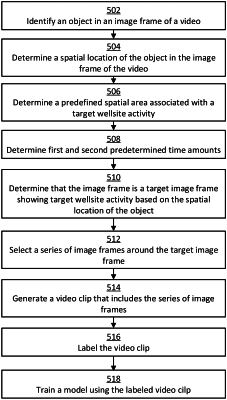
train a model with a set of training data to identify an object and a corresponding spatial location of the object in each image frame in a video depicting performance of a wellsite activity;
analyze a plurality of consecutive image frames in the video using the trained model to identify a target image frame in which the object is present in a predefined spatial area thereof, wherein the predefined spatial area is associated with performance of the wellsite activity; and
generate a video clip that includes only a subpart of the video based on the target image frame, the subpart including a series of consecutive image frames containing the target image frame.
|