| CPC G06F 16/245 (2019.01) [G06F 16/248 (2019.01); G06F 16/285 (2019.01); G06F 16/5866 (2019.01); G06F 18/22 (2023.01); G06F 18/23213 (2023.01); G06Q 30/04 (2013.01); G10L 15/26 (2013.01); G06N 3/04 (2013.01)] | 20 Claims |
|
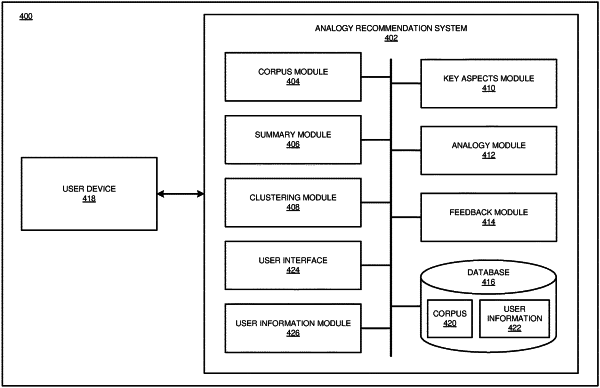
1. A computer-implemented method comprising:
identifying a plurality of data sources, wherein the plurality of data sources include accessible data related to a plurality of topics, wherein the plurality of topics include a first topic selected based on a user interest, and wherein the plurality of topics include a second topic selected based on an area of study for the user;
processing a dataset from the plurality of data sources using statistical modeling to generate a set of feature vectors by converting terms in the dataset into respective feature vectors corresponding to respective concepts, the set of feature vectors including a first feature vector converted from a first term corresponding to a first concept within the first topic and a second feature vector converted from a second term corresponding to a second concept within the second topic;
applying a clustering algorithm to the set of feature vectors to identify a set of clusters of feature vectors, wherein the set of clusters includes a first cluster of feature vectors and a second cluster of feature vectors, wherein the first cluster of feature vectors includes the first feature vector and the second cluster of feature vectors includes the second feature vector;
identifying, from among elements of the feature vectors, elements associated with key features that most contribute to influencing the clustering algorithm when identifying the set of clusters, wherein the key features include a first set of key features from the first feature vector and a second set of key features from the second feature vector;
selecting, responsive to a query from a user, the first feature vector based on a detected relevance between the first concept and the query;
selecting the second feature vector based at least in part on an overlap between the first set of key features and the second set of key features and a degree of dissimilarity between the first concept and the second concept;
outputting a first response to the query, wherein the response includes a first analogy relating the first term to the second term;
outputting a second response to the query, wherein the second response includes a second analogy relating the first term to the second term; and
determining a relative effectiveness value between the first analogy and the second analogy, wherein the relative effectiveness value is based at least in part on a comparison between the user's level of knowledge after the first analogy and the user's level of knowledge after the second analogy.
|