| CPC G05B 19/054 (2013.01) [G05B 19/05 (2013.01); G06F 9/54 (2013.01); G06F 16/212 (2019.01); G06F 16/254 (2019.01); G06F 16/9024 (2019.01); G06F 18/2178 (2023.01); G06F 18/24155 (2023.01); G06N 20/00 (2019.01); H04L 41/12 (2013.01); G05B 2219/1215 (2013.01); G05B 2219/13129 (2013.01); G05B 2219/15012 (2013.01); G05B 2219/163 (2013.01)] | 18 Claims |
|
1. A computer-implemented method comprising:
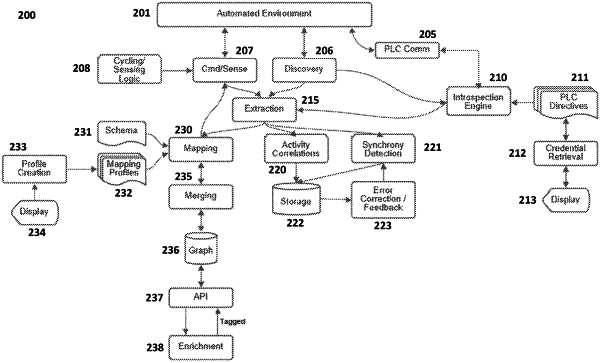
a) identifying a plurality of data sources associated with an automation environment;
b) retrieving data from at least one of the identified data sources, wherein the data is associated with a timestamp;
c) applying a first algorithm to map the retrieved data to a predetermined ontology, wherein the mapped data remains associated with the timestamp;
d) merging the mapped data into a data store comprising timeseries of the mapped data, wherein the data store comprises a graph database, wherein each vertex in the graph includes a timeseries store to capture data changes over time based on the timestamp associated with the mapped data, wherein merging the mapped data into the data store comprises matching mapped data with evolved vertices in the graph and merging new properties, shape details, or relationships into the matched vertices and timeseries data recorded in the vertex's timeseries store;
e) applying a second algorithm to identify patterns in the merged data and enriching the data based on one or more identified patterns, wherein the identified patterns are indicative of a relationship between one or more of the plurality data sources, wherein the relationship comprises a complete causal relationship, an incomplete causal relationship, or a correlational relationship, wherein enriching the data based on the one or more identified patterns comprises requesting creation or deletion of one or more vertices in the graph, one or more edges in the graph, one or more vertex properties in the graph, or one or more edge properties in the graph;
f) merging the enriched data into the data store to generate updated data and applying the second algorithm to further identify patterns in the updated data; and
g) providing one or more APIs or one or more real-time streams to provide access to the enriched data, the updated data, or both the enriched data and the updated data:
wherein the enriching the data is performed by a plurality of software agents, each configured to generate a specific enrichment, and wherein the enrichments are merged into the data store by origin tagging, wherein the origin tagging identifies the software agent that generated the enrichment.
|