| CPC G06T 19/006 (2013.01) [G06F 16/953 (2019.01); G06F 18/21 (2023.01); G06T 7/11 (2017.01); G06T 7/50 (2017.01); G06T 7/70 (2017.01); G06V 20/10 (2022.01); G06N 3/042 (2023.01); G06N 3/08 (2013.01); G06T 2207/20021 (2013.01); G06T 2207/20084 (2013.01)] | 17 Claims |
|
1. A computer-implemented method, comprising:
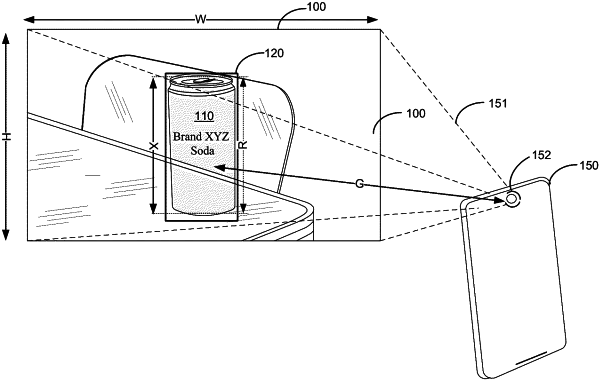
receiving a two-dimensional (2-D) still image of a scene captured by a camera;
recognizing at least one object in the scene depicted in the 2-D still image;
determining whether the at least one object has known dimensions including a known height corresponding to an image height of the at least one object in the 2-D still image;
segmenting the 2-D still image into a segmented object image portion containing the at least one object having the known dimensions;
calculating a depth from the camera of the segmented object image portion containing the at least one object using only the known height of the at least one object, an intrinsic parameter of the camera, and the image height of the at least one object;
preparing a depth map corresponding to the 2-D still image using the depth from the camera of the segmented object image portion containing the at least one object; and
overlaying augmented reality content over a display of the 2-D still image of the scene using the depth map to position the augmented reality content over the 2-D still image, wherein using the depth map to position the augmented reality content over the 2-D still image includes using the at least one object having the known dimensions present in the scene as a fiducial marker to determine a pose of the camera.
|