| CPC G06F 9/30036 (2013.01) [G06F 9/3001 (2013.01); G06F 9/3004 (2013.01); G06F 13/28 (2013.01); G06F 15/7821 (2013.01); G06N 3/045 (2023.01)] | 8 Claims |
|
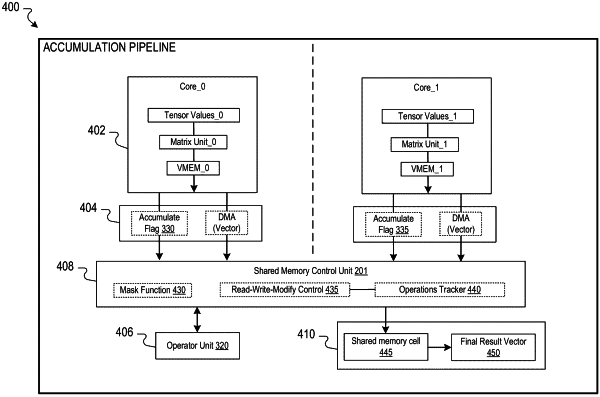
1. A method performed using an integrated circuit for a hardware machine-learning accelerator that includes a plurality of cores and a shared memory that communicates with each of the plurality of cores, the method comprising:
generating, by each of the plurality of cores, a respective vector of values;
performing, across the plurality of cores and into a shared memory cell in the shared memory, a plurality of atomic vector reductions using each of the respective vectors and an operator unit of the shared memory without synchronization; and
generating a result vector based on the plurality of atomic vector reductions.
|