| CPC H04L 41/0631 (2013.01) [H04L 41/149 (2022.05); H04L 43/0876 (2013.01)] | 16 Claims |
|
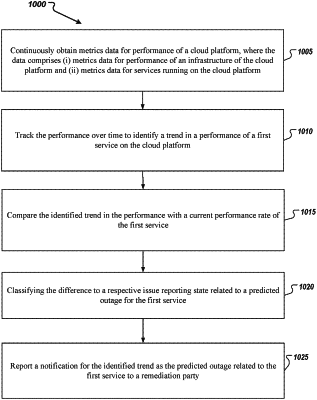
1. A computer-implemented method, the method comprising:
continuously obtaining metrics data for performance of a cloud platform, where the data comprises (i) infrastructure metrics data for performance of an infrastructure of the cloud platform and (ii) service metrics data for services running on the cloud platform;
tracking, based on evaluation of the obtained metrics data, the performance of the cloud platform over time to identify a trend in a performance of a first service on the cloud platform;
comparing the identified trend in the performance of the first service with a current performance rate of the first service, wherein the current performance rate is determined based on the continuously obtained metrics data comprising service metrics data for the first service;
based on an evaluated difference between the current performance rate and the identified trend in the performance of the first service, classifying the difference into an issue-reporting level associated with a prediction for an outage at the first service;
based on the issue-reporting level, reporting a notification for the identified trend in the performance of the first service as the predicted outage related to the first service to a remediation party, wherein the remediation party is selected from a group of parties, each party being associated with a different issue-reporting level matching likelihood of occurrence of the predicted outage at the first service; and
triggering a root cause analysis to identify a root cause issue on the cloud platform associated with the notification for the identified trend in the performance of the first service as the predicted outage related to the first service, wherein triggering the root cause analysis comprises:
collecting availability data for the cloud platform;
determining that at least a portion of a set of services running on the cloud platform are experiencing issues based on an evaluation of the collected availability data;
triggering a detailed checking to collect data logs, metrics, and dependencies data for at least the portion of the set of services running on the cloud platform;
determining an overall status of performance of the cloud platform based on obtained service status data from the detailed checking;
triggering execution of causal engine logic to identify an issue at the cloud platform based on analysis of the overall status of performance of the cloud platform; and
providing a notification for the identified issue.
|